
17.1 – Background
In the earlier chapter we had this discussion about the range within which Nifty is likely to trade given that we know its annualized volatility. We arrived at an upper and lower end range for Nifty and even concluded that Nifty is likely to trade within the calculated range.
Fair enough, but how sure are we about this? Is there a possibility that Nifty would trade outside this range? If yes, what is the probability that it will trade outside the range and what is the probability that Nifty will trade within the range? If there is an outside range, then what are its values?
Finding answers to these questions are very important for several reasons. If not for anything it will lay down a very basic foundation to a quantitative approach to markets, which is very different from the regular fundamental and technical analysis thought process.
So let us dig a bit deeper and get our answers.
17.2 – Random Walk
The discussion we are about to have is extremely important and highly relevant to the topic at hand, and of course very interesting as well.
Have a look at the image below –
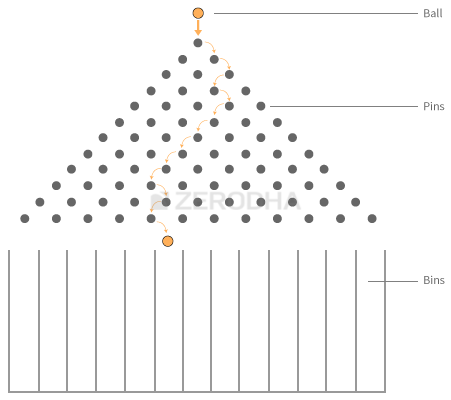
What you see is called a ‘Galton Board’. A Galton Board has pins stuck to a board. Collecting bins are placed right below these pins.
The idea is to drop a small ball from above the pins. Moment you drop the ball, it encounters the first pin after which the ball can either turn left or turn right before it encounters another pin. The same procedure repeats until the ball trickles down and falls into one of the bins below.
Do note, once you drop the ball from top, you cannot do anything to artificially control the path that the ball takes before it finally rests in one of the bins. The path that the ball takes is completely natural and is not predefined or controlled. For this particular reason, the path that the ball takes is called the ‘Random Walk’.
Now, can you imagine what would happen if you were to drop several such balls one after the other? Obviously each ball will take a random walk before it falls into one of the bins. However what do you think about the distribution of these balls in the bins?.
- Will they all fall in the same bin? or
- Will they all get distributed equally across the bins? or
- Will they randomly fall across the various bins?
I’m sure people not familiar with this experiment would be tempted to think that the balls would fall randomly across various bins and does not really follow any particular pattern. But this does not happen, there seems to be an order here.
Have a look at the image below –
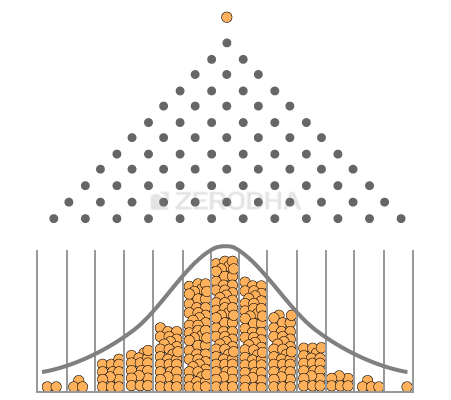
It appears that when you drop several balls on the Galton Board, with each ball taking a random walk, they all get distributed in a particular way –
- Most of the balls tend to fall in the central bin
- As you move further away from the central bin (either to the left or right), there are fewer balls
- The bins at extreme ends have very few balls
A distribution of this sort is called the “Normal Distribution”. You may have heard of the bell curve from your school days, bell curve is nothing but the normal distribution. Now here is the best part, irrespective of how many times you repeat this experiment, the balls always get distributed to form a normal distribution.
This is a very popular experiment called the Galton Board experiment; I would strongly recommend you to watch this beautiful video to understand this discussion better –
So why do you think we are discussing the Galton Board experiment and the Normal Distribution?
Well many things in real life follow this natural order. For example –
- Gather a bunch of adults and measure their weights – segregate the weights across bins (call them the weight bins) like 40kgs to 50kgs, 50kgs to 60kgs, 60kgs to 70kgs etc. Count the number of people across each bin and you end up getting a normal distribution
- Conduct the same experiment with people’s height and you will end up getting a normal distribution
- You will get a Normal Distribution with people’s shoe size
- Weight of fruits, vegetables
- Commute time on a given route
- Lifetime of batteries
This list can go on and on, however I would like to draw your attention to one more interesting variable that follows the normal distribution – the daily returns of a stock!
The daily returns of a stock or an index cannot be predicted – meaning if you were to ask me what will be return on TCS tomorrow I will not be able to tell you, this is more like the random walk that the ball takes. However if I collect the daily returns of the stock for a certain period and see the distribution of these returns – I get to see a normal distribution aka the bell curve!
To drive this point across I have plotted the distribution of the daily returns of the following stocks/indices –
- Nifty (index)
- Bank Nifty ( index)
- TCS (large cap)
- Cipla (large cap)
- Kitex Garments (small cap)
- Astral Poly (small cap)
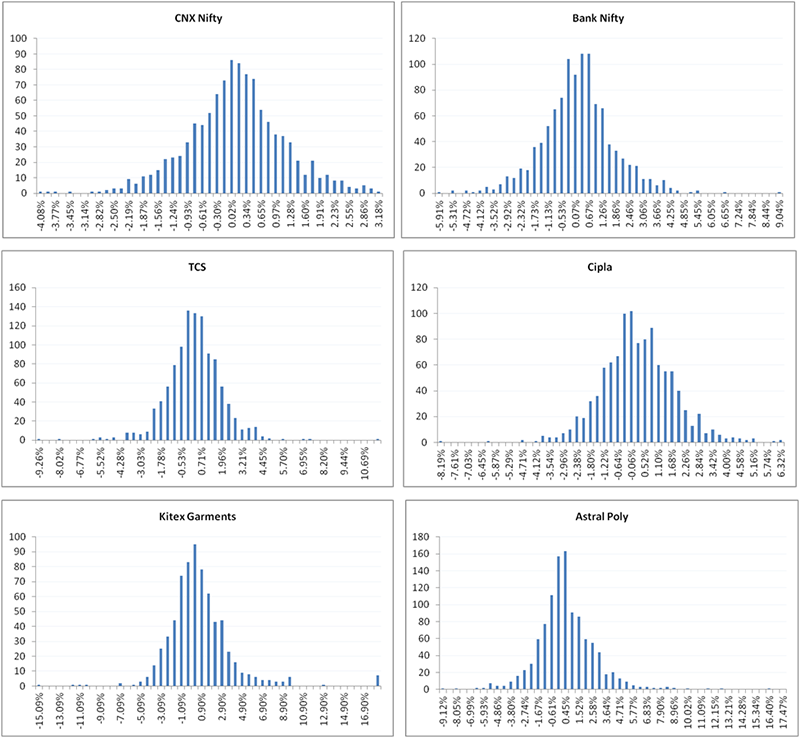
As you can see the daily returns of the stocks and indices clearly follow a normal distribution.
Fair enough, but I guess by now you would be curious to know why is this important and how is it connected to Volatility? Bear with me for a little longer and you will know why I’m talking about this.

17.3 – Normal Distribution
I think the following discussion could be a bit overwhelming for a person exploring the concept of normal distribution for the first time. So here is what I will do – I will explain the concept of normal distribution, relate this concept to the Galton board experiment, and then extrapolate it to the stock markets. I hope this will help you grasp the gist better.
So besides the Normal Distribution there are other distributions across which data can be distributed. Different data sets are distributed in different statistical ways. Some of the other data distribution patterns are – binomial distribution, uniform distribution, poisson distribution, chi square distribution etc. However the normal distribution pattern is probably the most well understood and researched distribution amongst the other distributions.
The normal distribution has a set of characteristics that helps us develop insights into the data set. The normal distribution curve can be fully described by two numbers – the distribution’s mean (average) and standard deviation.
The mean is the central value where maximum values are concentrated. This is the average value of the distribution. For instance, in the Galton board experiment the mean is that bin which has the maximum numbers of balls in it.
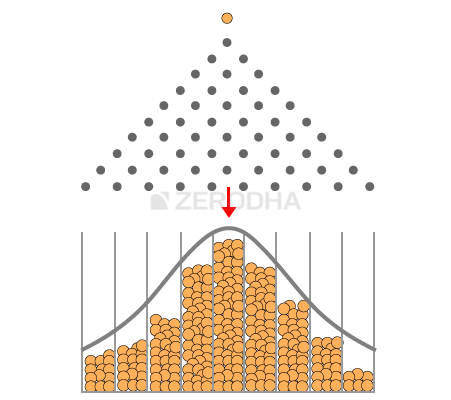
So if I were to number the bins (starting from the left) as 1, 2, 3…all the way upto 9 (right most), then the 5th bin (marked by a red arrow) is the ‘average’ bin. Keeping the average bin as a reference, the data is spread out on either sides of this average reference value. The way the data is spread out (dispersion as it is called) is quantified by the standard deviation (recollect this also happens to be the volatility in the stock market context).
Here is something you need to know – when someone says ‘Standard Deviation (SD)’ by default they are referring to the 1st SD. Likewise there is 2nd standard deviation (2SD), 3rd standard deviation (SD) etc. So when I say SD, I’m referring to just the standard deviation value, 2SD would refer to 2 times the SD value, 3 SD would refer to 3 times the SD value so on and so forth.
For example assume in case of the Galton Board experiment the SD is 1 and average is 5. Then,
- 1 SD would encompass bins between 4th bin (5 – 1 ) and 6th bin (5 + 1). This is 1 bin to the left and 1 bin to the right of the average bin
- 2 SD would encompass bins between 3rd bin (5 – 2*1) and 7th bin (5 + 2*1)
- 3 SD would encompass bins between 2nd bin (5 – 3*1) and 8th bin (5 + 3*1)
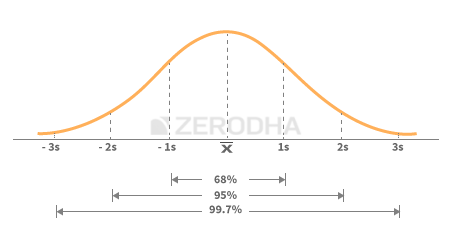
Now keeping the above in perspective, here is the general theory around the normal distribution which you should know –
- Within the 1st standard deviation one can observe 68% of the data
- Within the 2nd standard deviation one can observe 95% of the data
- Within the 3rd standard deviation one can observe 99.7% of the data
The following image should help you visualize the above –
Applying this to the Galton board experiment –
- Within the 1st standard deviation i.e between 4th and 6th bin we can observe that 68% of balls are collected
- Within the 2nd standard deviation i.e between 3rd and 7th bin we can observe that 95% of balls are collected
- Within the 3rd standard deviation i.e between 2nd and 8th bin we can observe that 99.7% of balls are collected
Keeping the above in perspective, let us assume you are about to drop a ball on the Galton board and before doing so we both engage in a conversation –
You – I’m about to drop a ball, can you guess which bin the ball will fall into?
Me – No, I cannot as each ball takes a random walk. However, I can predict the range of bins in which it may fall
You – Can you predict the range?
Me – Most probably the ball will fall between the 4th and the 6th bin
You – Well, how sure are you about this?
Me – I’m 68% confident that it would fall anywhere between the 4th and the 6th bin
You – Well, 68% is a bit low on accuracy, can you estimate the range with a greater accuracy?
Me – Sure, I can. The ball is likely to fall between the 3rd and 7th bin, and I’m 95% sure about this. If you want an even higher accuracy then I’d say that the ball is likely to fall between the 2nd and 8th bin and I’m 99.5% sure about this
You – Nice, does that mean there is no chance for the ball to fall in either the 1st or 10th bin?
Me – Well, there is certainly a chance for the ball to fall in one of the bins outside the 3rd SD bins but the chance is very low
You – How low?
Me – The chance is as low as spotting a ‘Black Swan’ in a river. Probability wise, the chance is less than 0.5%
You – Tell me more about the Black Swan
Me – Black Swan ‘events’ as they are called, are events (like the ball falling in 1st or 10th bin) that have a low probability of occurrence. But one should be aware that black swan events have a non-zero probability and it can certainly occur – when and how is hard to predict. In the picture below you can see the occurrence of a black swan event –
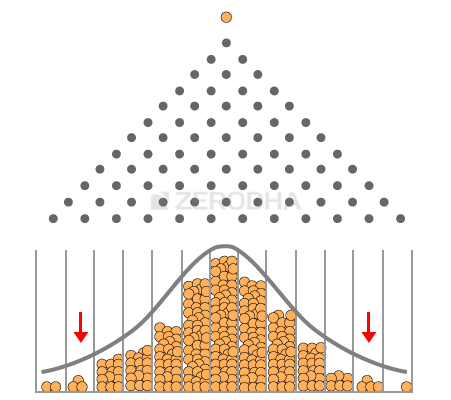
In the above picture there are so many balls that are dropped, but only a handful of them collect at the extreme ends.
17.4 – Normal Distribution and stock returns
Hopefully the above discussion should have given you a quick introduction to the normal distribution. The reason why we are talking about normal distribution is that the daily returns of the stock/indices also form a bell curve or a normal distribution. This implies that if we know the mean and standard deviation of the stock return, then we can develop a greater insight into the behavior of the stock’s returns or its dispersion. For sake of this discussion, let us take up the case of Nifty and do some analysis.
To begin with, here is the distribution of Nifty’s daily returns is –
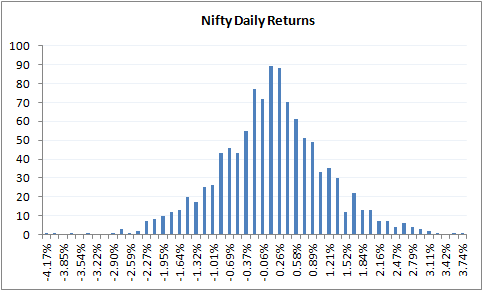
As we can see the daily returns are clearly distributed normally. I’ve calculated the average and standard deviation for this distribution (in case you are wondering how to calculate the same, please do refer to the previous chapter). Remember to calculate these values we need to calculate the log daily returns.
- Daily Average / Mean = 0.04%
- Daily Standard Deviation / Volatility = 1.046%
- Current market price of Nifty = 8337
Do note, an average of 0.04% indicates that the daily returns of nifty are centered at 0.04%. Now keeping this information in perspective let us calculate the following things –
- The range within which Nifty is likely to trade in the next 1 year
- The range within which Nifty is likely to trade over the next 30 days.
For both the above calculations, we will use 1 and 2 standard deviation meaning with 68% and 95% confidence.
Solution 1 – (Nifty’s range for next 1 year)
Average = 0.04%
SD = 1.046%
Let us convert this to annualized numbers –
Average = 0.04*252 = 9.66%
SD = 1.046% * Sqrt (252) = 16.61%
So with 68% confidence I can say that the value of Nifty is likely to be in the range of –
= Average + 1 SD (Upper Range) and Average – 1 SD (Lower Range)
= 9.66% + 16.61% = 26.66%
= 9.66% – 16.61% = -6.95%
Note these % are log percentages (as we have calculated this on log daily returns), so we need to convert these back to regular %, we can do that directly and get the range value (w.r.t to Nifty’s CMP of 8337) –
Upper Range
= 8337 *exponential (26.66%)
= 10841
And for lower range –
= 8337 * exponential (-6.95%)
= 7777
The above calculation suggests that Nifty is likely to trade somewhere between 7777 and 10841. How confident I am about this? – Well as you know I’m 68% confident about this.
Let us increase the confidence level to 95% or the 2nd standard deviation and check what values we get –
Average + 2 SD (Upper Range) and Average – 2 SD (Lower Range)
= 9.66% + 2* 16.61% = 42.87%
= 9.66% – 2* 16.61% = -23.56%
Hence the range works out to –
Upper Range
= 8337 *exponential (42.87%)
= 12800
And for lower range –
= 8337 * exponential (-23.56%)
= 6587
The above calculation suggests that with 95% confidence Nifty is likely to trade anywhere in the range of 6587 and 12800 over the next one year. Also as you can notice when we want higher accuracy, the range becomes much larger.
I would suggest you do the same exercise for 99.7% confidence or with 3SD and figure out what kind of range numbers you get.
Now, assume you do the range calculation of Nifty at 3SD level and get the lower range value of Nifty as 5000 (I’m just quoting this as a place holder number here), does this mean Nifty cannot go below 5000? Well it certainly can but the chance of going below 5000 is low, and if it really does go below 5000 then it can be termed as a black swan event. You can extend the same argument to the upper end range as well.
Solution 2 – (Nifty’s range for next 30 days)
We know the daily mean and SD –
Average = 0.04%
SD = 1.046%
Since we are interested in calculating the range for next 30 days, we need to convert the same for the desired time period –
Average = 0.04% * 30 = 1.15%
SD = 1.046% * sqrt (30) = 5.73%
So with 68% confidence I can say that, the value of Nifty over the next 30 days is likely to be in the range of –
= Average + 1 SD (Upper Range) and Average – 1 SD (Lower Range)
= 1.15% + 5.73% = 6.88%
= 1.15% – 5.73% = – 4.58%
Note these % are log percentages, so we need to convert them back to regular %, we can do that directly and get the range value (w.r.t to Nifty’s CMP of 8337) –
= 8337 *exponential (6.88%)
= 8930
And for lower range –
= 8337 * exponential (-4.58%)
= 7963
The above calculation suggests that with 68% confidence level I can estimate Nifty to trade somewhere between 8930 and 7963 over the next 30 days.
Let us increase the confidence level to 95% or the 2nd standard deviation and check what values we get –
Average + 2 SD (Upper Range) and Average – 2 SD (Lower Range)
= 1.15% + 2* 5.73% = 12.61%
= 1.15% – 2* 5.73% = -10.31%
Hence the range works out to –
= 8337 *exponential (12.61%)
= 9457 (Upper Range)
And for lower range –
= 8337 * exponential (-10.31%)
= 7520
I hope the above calculations are clear to you. You can also download the MS excel that I’ve used to make these calculations.
Of course you may have a very valid point at this stage – normal distribution is fine, but how do I get to use the information to trade? I guess as such this chapter is quite long enough to accommodate more concepts. Hence we will move the application part to the next chapter. In the next chapter we will explore the applications of standard deviation (volatility) and its relevance to trading. We will discuss two important topics in the next chapter (1) How to select strikes that can be sold/written using normal distribution and (2) How to set up stoploss using volatility.
Of course, do remember eventually the idea is to discuss Vega and its effect on options premium.
Key takeaways from this chapter
- The daily returns of the stock is a random walk, highly difficult to predict
- The returns of the stock is normally distributed or rather close to normal distribution
- In a normal distribution the data is centered around the mean and the dispersion is measured by the standard deviation
- Within 1 SD we can observe 68% of the data
- Within 2 SD we can observe 95% of the data
- Within 3 SD we can observe 99.5% of the data
- Events occurring outside the 3rd standard deviation are referred to as Black Swan events
- Using the SD values we can calculate the upper and lower value of stocks/indices
I am facing problems understanding IV, especially for T and rate values. NSE is using R as 10%, whereas every platform is indicating to use rate of 91 dat t-bill ? Which one to use ?
Please check the response to the previous comment.
I am facing problems understanding Implied volatality, especially for T and rate values. If, going by the NSE white paper for India VIX, T value is number of trading days/ 252, then why is NSE taking interest rate as 10%???
Hey Vishu, not sure why NSE considers 10%. Also I\’m not fully sure if I understand your query – T = number of trading days which you got right, but unable to understand this part – then why is NSE taking interest rate as 10%???
Suppose I\’m calculating SD for a particular period, so should I consider the holidays in the time period or just consider the days , when markets are open ? Also what if I get a negative average for returns after all my calculation what do I do then ?
You can consider the number of trading days. You will get -ve only if the stock has been trending down for a long time.
Karthik sir, off late I\’ve been reading books by Nassim Nicholas Taleb and he says that models like black scholes, normal distribution, VaR are useless because they ignore real world risks and fat tails as he calls them. What do you think about it? Should I as a retail trader worry about reliability of these models? Taleb is really interesting guy but also complex to read sometimes. Your guidence please.
I cant really dispute what Taleb says, but that said, treat this as a reference point to give you a sense of what should be the price. That approach should be good to go with I guess.
Karthik sir,
In the normal distribution that you plotted for Nifty 50 & other stocks, what is the parameter on the Y-axis ? From where the Y-axis value has been taken, pls clarify.
Its the number of observations Vaishak. As in how many times a certain return has occurred in the timeline you are studying. For example – A return of 5% has occurred 15 times over the last 1 year.
As it is daily returns so assume it as number of days
Sorry, dint get the query. Can you please elaborate? Thanks.
Hi Sir,
why Bin width divided by 50 ? and is it the same for stocks and other Index? Please guide.
and one more question sir,
Do we need to take five years data as base to calculate? as I can see you took data for 5 years (2011 to 2015).
5 years is good, but if you have a shorter term approach, then even last 2 years is fine.
Yes, its independent of the underlying asset. The idea is to look at the size of the data set and then take a call on how many bins etc.
Hello Karthik Sir, I am back after a long time as I can\’t forget the impact of these chapters. I am not able to download your sample Excel for the Normal Distribution calculation. Could you please help here? I think some issue.
Hi Suvajit, welcome back 🙂
It seems to be working fine for me. Try changing the browser?
Hi Karthik,
I want to calculate the Nifty range for July 25. Which period of historical Nifty data should be used for this calculation? (1-04-24) to (31-04-25) or (01-06-24) to (01-06-25) or (01-06-25 to 30-06-25)
Thank You 🙂
I\’d suggest you use the latest 1 year data for this, Soham.
Hi Sir, Excellent way of teaching. Some people are born natural teachers. I had one query, why have you divided by 50 in Binary width calculation in excel?
Thanks for the kind words, Rahul. 50 is an arbitrary number arrived at based on the number of data points.
Is it fair to say that arbitrary number should be such that the normal distribution graph looks symmetrical from both sides? Nifty example, you have taken 50 but when I take the same for Kotak Bank, the graph is a bit asymmetrical. Hence I have used 43 such that maximum values lie in the middle of the X-axis.
One thing you can do is think of it in this way – for every n number of data points, have y bins,
sir in the annual volatility formula if we take days 365 in all the cases then it is more reliable than the taking no. of observation we took in the SD formula. eg. =1.04%*SQRT(365). I m suggesting you to calculate annual volatility by taking always 365 days and then compare it with nse website data. i have check it many times and it is always same as nse data rather than taking no. of observations.
And because of this im not getting calculation part further .
Do check it and if find same observation as me then change the calculation data.
There is a fundamental difference between this method and NSE\’s computation of volatility. NSE does this mainly in terms of figuring the margin required for position, where in they give more weightage to recent data points. Where as, in this method discussed, we give equal weights to all data points as the objective is to simlply figure the overall volatility of the instruments. Hence there will be some difference in the final volatility values of this method vs NSE\’s.
\”You – Tell me more about the Black Swan
Me – Black Swan ‘events’ as they are called, are events (like the ball falling in 1st or 10th bin) that have a low probability of occurrence. But one should be aware that black swan events have a non-zero probability and it can certainly occur – when and how is hard to predict. In the picture below you can see the occurrence of a black swan event –
In the above picture there are so many balls that are dropped, but only a handful of them collect at the extreme ends.\”
I would like to add that \”While it’s true that Black Swan events are rare (‘only a handful collect at the extreme ends’), the real issue isn’t their frequency—it’s their catastrophic impact, as they can wipe out years of steady profits overnight and even push businesses or investors into bankruptcy. History has repeatedly shown this: the 1929 Great Depression saw the Dow Jones plunge 89%, leading to mass unemployment; the 1973 Oil Crisis triggered a global recession with markets falling 48%; Black Monday (1987) wiped out 22% of the U.S. stock market in a single day; the 1997 Asian Financial Crisis led to currency collapses and stock declines of over 60% in some economies; the 2000 Dot-com Bubble erased 78% of the Nasdaq’s value; the 2008 Global Financial Crisis led to a 54% decline in the S&P 500, causing widespread bankruptcies; and the 2020 COVID-19 Crash saw global markets plummet 30% in weeks, disrupting entire industries. These crises prove that it’s not enough to acknowledge that Black Swans can happen—their disproportionate impact makes risk management and preparedness far more important than probability estimates.\”
What do you think?
Yes sir. Thats right.
Hi Karthik, yes, I understood the plots now. Thanks a lot.
Happy learning, Pradeep!
Sorry for my mistake here. I wrote \”The question is what does the Y axis represent? It seems to be some normalised scale of the pricing of the index or equity closing value\”. It should read \’normalised on some scale of the daily return (or whatever period of interest we are using– such as annual or quarterly return etc). The rest of the query remains the same: how is \’the return percentage\’ normalised? That is, what does 100 represent?
Apologies for this inconvenience.
Please do check my previous response, let me know if it makes sense.
Please excuse me for asking this so late. Also, since all earlier comments are very appreciative of this article, it is very likely its me who is getting it all wrong. But please allow me to ask this rather fundamental question.
Firstly, I\’d like to clarify I am not into F&O, but was directed here, by your Chapter 22 on MF parameters, to understand SD calculations and how could they be applied to MF risk evaluation.
https://zerodha.com/varsity/chapter/mutual-fund-risk-metrics/
So, in all above plots on normal distribution, it is my understanding that the X axis is the Standard Distribution in percent. The question is what does the Y axis represent? It seems to be some normalised scale of the pricing of the index or equity closing value. But then what is the process of this norrmalisation? In other words, what does 100 represent? By the same token, you also represent the Average of the entity (Index or equity price) over the period of interest as a certain percentage. So, I wonder percentage of what— (put differently, what is \’100\’ on this scale)?
Thanks in advance.
Hi Pradeep, so the Y axis represents the number of times a certain event has occurred. For example, in the Bank Nifty case, you can see a return of 0.07% has occurred 100 times, so has a return of 0.67%.
Sir you are really outstanding way to explain the every chapter till now what I read.Thank you so much for such great way explain everything.🙏🙏🙏🙏🙏🙏🙏🙇🙇🙇🙇
Thanks for the kind words, and happy learning, Bapi!
Very Informative Data
Happy learning 🙂
Can you please enable a dark mode for this website. Since I am reading from laptop, the large white background is straining my eyes and even in the lowest brightness settings it\’s still very bright.
Noted. You can also check the mobile app.
Sir. How to calculate daily mean / average?
I\’ve explained this in detail in this or the next chapter. But here are the steps –
1) Calculate the daily returs
2) Use excel function \’=Avg()\’, across all these returns to get the daily average return.
Thats it.
Sir in the example of nifty above you have calculated the daily returns right? (0.04%) and the daily volatility is represented as SD. So can you show how to you have calculated the Daily Returns Just for 1 or 2 days with the formula…..
I\’ve replied to your previous comment, please do check. Thanks.
Hi karthik Sir,
Here for nifty mean you have mentioned 0.04% but how did you arrive this value. Because the first value that we will derive from the last chapter was Daily volatility which is SD. So to calculate this mean is there a formula. Like for mean its always = outcomes/No of occurrences. How to get the daily average mean for indices and for any equity?
That is quite easy, in excel you first calculate the daily returns of the stock and then use the \’=Average()\’, function over the daily returns to get the mean.
sir can you explain why you multiply with exponential to the market price instaed of doing market price (1 +or- %)
sir in some examples you calculate range within directly without using daily mean .. then how to know the percentage of confidence weather 68% or 95% or 99%
when calculating the upper and lower ranges in the above examples every time you say \”Note these % are log percentages (as we have calculated this on log daily returns), so we need to convert these back to regular %, we can do that directly and get the range value\” my question here is that why calculate in logarithmic format why not we calculate simply in regular % in the first place \”or\” is that when we calculate for a larger period of time it automatically gets converted into logarithmic and we have convert it back into normal ?
If its for short data range, you can do that. No need to take log.
Excel sheet links are not working
Can you try downloading from another browser?
I am getting negative value for daily returns average. It\’s giving lower and higher end greater than current price. Is it normal?
If the stock is trending lower, then yes, why not 🙂
Thank you
zerodha team and specially karthik rangappa for taking pain
of reading our query and replying
thanks a lot
Happy learning, Javed!
MS excel download is not working
where is excel file
Try downloading from a different browser.
Hi did the equation
my answer differs
==============================
as in the chapter…………………….10841
Upper Range
8337 *exponential (26.66%)
10841
=====================================
i tried to solve mine is coming to ……….10560
26.66% of 8337
is 2222.6
8337+2223=10560
how is yours coming 10841 ???
YOu need to ensure you are using the exponential function on excel.
pls explain this equation
Upper Range
= 8337 *exponential (26.66%)
= 10841
please explain this
= 8337 *exponential (12.61%)
= 9457 (Upper Range)
Its a calculation. Have explained in the chapter itself.
sir
how do we calculate this
= 8337 *exponential (6.88%)
= 8930
You can apply this function on excel and get the answer.
I have a doubt like how to calculate the daily average of nifty 50
i couldnot understand thatr one
Daily average of what? Returns or price change? If its returns you calculate the daily returns, and apply the average function over the time series.
Very informative!! what is data range used to calculated SD, is it past 1 year data or 2 year or what?
You can stick to 1 year.
Sir, I am not able to download the excel sheet can you please fix the problem
Can you try downloading from another browser? Usually that works.
Hi karthik,
Not able to download excel..please send link
Can you try from another browser?
Hello Karthick sir,
1. as per your guidance & steps calculated SD for Nifty 50 & Finnifty but the Mean Average turnedd out to be in Negative marks ex(-0.05), in that case how shall we calculate the prediction range month ahead from today ?
2. (like -*- = + will it applicable in calculaton or were i wring in XL calculation…..
3. What shall we do now in prediction????????
The mean is usually a very small number, close to zero. So this is not surprising. That said, I\’d still suggest you double check all the numbers and calculation steps once again.
Hi Karthik, I am constantly learning from your beautifully crafted material, it is practical and really helpful. Thanks for that!
Question: Nifty’s range for next 30 days (7963 – 8930) calculated. Lets say Nifty drop or jump significantly in next session and new data come into the data series for next day and range keep changing constantly for defined period of next 30 days. Shall we focus on the range calculated on first day for next 30 days Or need to keep an eye simultaneously on changing range on the basis of new data come into the data series? Only first range is sufficient or keep an eye on both?
Thanks Navneet. If there is new data and there is significant change, then you should consider and reevaluate using the new data 🙂
Interesting insights about normal distribution and finding the relation with real time examples. Thanks for enriching our learning.
Glad you liked it Raman, happy learning 🙂
Dear Sir/Madam,
As stock prices cannot take negative values, instead of standard normal distribution consider log-normal distribution. In log-normal distribution, the stock price always take positive values. In standard normal distribution, stock price can take negative values which is impossible.
We deal with returns, which can be -ve right?
How do I visualize the daily return data in excel? I have calculated the daily return and std deviation for a few other instruments
You can plot a simple line chart to visualize.
Unfortunately Nifty does not allow down loading 4 years data in one shot, and I am unable to edit the formulae to reduce the lines to 253, any solution
Thanks
Yeah, you will have to do this one year at a time.
Sir, I was referring to which method should I use for calculating the standard deviation, did you say to first back test the one you explained in this module in your last response?
Yes, I\’d suggest you back test it once and see how the volatility model behaves before you actually deploy cash.
Thanks for the reply, sir. Which one should I use for volatility calculation if I want to know near which standard deviation is the stock trading (meaning 1sd, 2sd), if I am planning a reversion strategy?
I\’d suggest you look at 2SD and backtest it see what sort of results you get. You can keep tweaking the system from there to arrive at an optimal SD for your risk appetite.
Hi Sir
I understand this method of calculating the annual standard deviation, but I tried calculating the standard deviation of Bosch Limited and there was a difference of 4% from the nse website, and they\’re using a different formula to calculate the standard deviation, which is,[Current Day Underlying Daily Volatility (E) = Sqrt(0.995*D*D + 0.005*C*C)],
They are giving 95% weightage to the previous day volatility. I got this from the daily nse report of volatility. But I\’m unable to understand how are the calculating this previous day volatility? And also which formula should I use the log returns one or this one?
Thanks.
Thats right, exchanges give more weightage to recent data because they need to calculate the margins for contracts. However, the method we are discussing here gives equal weight to all data points and hence the difference.
Respected Sir.
Sir I am very new to trading and some little amount I have invested by reading your fundamental analysis which have grown 5times in 3 year.
Without your guidance I could not have made that money.
Kartik Sir I have a doubt that can I use Heikena Ashi candle for trading Without candle stick ?
Why candle stick is famous ?
I am extremely sorry I am asking in the middle of this chapter.
Very happy to note that, I hope both your understanding of markets and your funds grow over the years 🙂
About Heikena Ashi, I cant really comment as I;ve never used it myself. Thats the reason I\’ve not covered it in TA module as well. Candles is popular because of its simplicity of use.
Good Morning Sir.
Sir I am unable to download the EXCLE.
PLEASE help.
Can you try to downloading from another browser?
Got it sir. It was just a rounding off error
Sure. Glad you figured 🙂
Average = 0.04*252 = 9.66%
Sir when I am doing this calculation in excel I am getting 10.08%,
Not sure, maybe double check the maths?
How to calculate the mean returns for the for the stock.
Have explained in the chapter itself.
Thank you karthik sir this is such a blissful reading experience beautifully crafted
Thanks Syed. Happy learning 🙂
sir i am doing study now so excel sheet is not opening so how to go for average and sd to find out the range
Can you please try another browser?
Hi Sir – How to calculate the daily average for NIFTY in the above example(0.04%) ?
It is clear from prev chapter that the daily volatility can be calculated using STDEV(std deviation).
Thanks
Naveen, are you refering to daily avg returns or daily avg volatility? If its the returns, then calculate the daily return, that will give you a time series of data, calculate the average over it, thats it.
Can you please help with a formula to convert those logarithm percentages to normal percentages, also the sheet link is not working can you please provide the sheet link in comment section.
You can use the exponential function i.e. \’=exp()\’, on excel to convert log to regular values.
Dear Karthik,
Please correct me if I am wrong brother. I am a newbie in finance; reading a lot these days.
But going by your logic, closing price of friday 3 30 should be exact same match as opening price on Monday 9 30?
Plus, Profits and losses are also made on saturdays and sundays (by the company), and implied volatility should also work during market off days(theoretically speaking)!
Volatility is a mathemetical equation. It should be biased towards Holidays!
So thats why I was asking, why sqrt of 252 and not sqrt 365.
pardon my ignorance
Regards
hello dear. I would like to humbly point out that RMS of 365 is 19.1 and of 252 is 15.87. If we calculate annualised and daily volatility by using sqrt252 days, it gives us the wrong answer, while the correct answer can be acheived by taking 19.1 as the factor.
My logic:
Although market trades only functions for 252 days/yr, the share value (conceptually) varies all 365 days in the year. Hence accurate values can be acheived by using 19.1 instead of sqrt252
Regards
Dr Prashant Bansal
Thanks, but how will the stock price vary when markets are closed?
SD = 1.046% * Sqrt (252) = 16.61%
Time last chapter mai 365 liya tha. Es chapter mai 252. Total number of days in a year OR working days of Stock market?? Kaunsa select Lena hai
Go with the first approach.
How to get Daily Average / Mean of stock?
You can use a simple moving average on kite for this, Tarun.
sir using this i have calculted it for nifty bank data 24-09-23 to 24-10-23 i have get the mean of -0.19 and SD is 0.67 here mean is in -ve then i am getting the values like -44.65% etc could you check it clarify it to me
This can happen when the prices have trended down for a few days within the time duration under consideration.
Hi Karthik,
First of all let me congratulate you on completing 13 years of zerodha!!!
I would really appreciate it if you can answer my following questions.
1)When measuring volatility as you mentioned in the module 5 (historical volatility ) to download 1 year data, is that true for every time?
2) if i\’m doing back testing and using 1 year data, for expontial calculation how to chose the spot price?(open/close)
really appreciate your response!!
Thank you 🙂
1) Yeah, gives you a good perspective 🙂
2) Always go for close prices.
Karthik sir, you are truly a great teacher. You taught us differentiation, standard deviation, normal distribution, and much more with so ease.
You should be on one of the school curriculum designers\’ committees.
Thanks for the kind words, happy learning Sujay 🙂
KARTHIK SIR
I have mailed them and they replied that they calculate SD this way:
When the SD setting is set to Fixed SD, the formula to calculate the Standard Deviation is Current Spot Price x ATM IV x 0.01 x square root (days set in Fixed SD / 365 days). To get 1 SD and -1 SD values, the SD is added and subtracted from the current spot price
Sure. Thanks for sharing, I hope that helped you as well.
Sir When we access the strategy builder in Sensibull and create our buy or sell strategy, we can observe that at the bottom of the interface, there are options for selecting either 1SD or 2SD for the specific indices we are trading. However, upon my calculation, I noticed that my results differ from those provided by Sensibull. They do not incorporate the mean into their 1SD and 2SD values, and their calculations seem to be based on monthly data, which does not yield a proper distribution on graph.
Ah, ok. I\’ve not checked their graphs for this. Not sure about this, maybe you can write to them for an explanation as to why monthly data and not weekly. Thanks.
Sir small doubt in key takeaways of the chapter you have written this
Within 1 SD we can observe 68% of the data
Within 2 SD we can observe 95% of the data
Within 3 SD we can observe 99.5% of the data
but don\’t you think it should be
Within 1 SD + MEAN we can observe 68% of the data
Within 2 SD + MEAN we can observe 95% of the data
Within 3 SD + MEAN we can observe 99.5% of the data
The mean is usually really small value, and does not make a big difference in my opinion.
Hello, sir. The Excel sheet link is not working. Could you please provide the Excel sheet?
Can you try downloading from another browser, Rajdeep?
Hi Mr. Karthik,
Thanks for providing the option trading related content.
Can you pls help me? how can i download the excel file from the given link? I am trying but excel sheet is not downloading.
Ajay, can you try downloading this from another browser?
how to convert log % to normal %
Have explained in the chapter itself, kindly check once.
Could you please explain how Daily average mean is calculated. Formula please
We have discussed that in the chapter itself, Vivek.
How to Plot this normal distribution graphs..??
Have explained that in the chapter itself.
Hello sir,
Kudos! I\’ve learnt alot of practical things from you, through these trading series. Thank you giving such an indepth knowledge. I\’ve a question , it\’d be quite helpful if you could help me out.
I\’ve done analysis of volatity of stock market over past 7 years ( by month wise month and year on year). It adhered to volatility points. But I\’m not able to make normal distribution curve, I\’m getting confused what to consider as range for making bar graph?
Glad you liked the content, Archit. There is no hard science as to how to choose the range, number of bins, bin width. You can have maybe 15 or 20 bins and see how the chart turns out and improvise on that.
Hi Karthik, Amazing learnings so far. I just have question. You did a calculation of \”Average = 0.04*252 = 9.66%\” Ideally it should have been 10.08% right?
Ah, looks like a typo 🙂
hi, in that case, where do we stand with vix? it seems that 16.6% (sd) is average vix. but when vix is higher, say 25, since the average is 16, wouldnt this approximation be invalid, or is there an adjustment? also, what is the ideal number of recent data that one should use for this calculation to predict the confidence levels of nifty?
Its not invalid, it just means the fear in the market has increased and therefore the ViX has shot up. There is no adjustment required. Also no ideal number, Madhur.
Sir, i\’ve scratched my head numerous times over converting log percentage to normal percentage? i\’ve tried to search on google, but couldn\’t find a way..
Can you please show me how its done?
Ram, I\’ve explained this in this (or maybe the next) chapter. You use exponential form for this.
I am unable to download the excel which you have shared for the calculation. Is the link still alive?
Yeah, try downloading using another browser Sudip.
Hi Karthik,
Regarding Chapter 17, Volatility & Normal Distribution, i have a query regarding the mean (average) number used. I want to understand the average of data is derived from \”log returns\” or actual daily returns?
Your reply to with with be highly appreciated.
Thank you
I\’ve used both to showcase both techniques. You can use either, Vinit.
and also how did you take bin width value as 50
and one more request from my side sir
can you please make a pdf for sectorial analysis as you have did for other modules and its my humble request that please start a youtube channel and please educate us about these practical scenarios because no course which is collecting more than 1 lakh rupees to teach stock market can beat your content which is provided for free. Thank you for your valuable resources sir it helped me a lot and please do consider my request its my humble request🙏
Ranganath, we have just started the sector analysis module. We will provide the PDF when its all done 🙂
I landed to one of the most prestigious content for option trading. Thankyou for providing such a valuable content sir.
Sir i have a simple doubt
As you have shared Nifty Calculations in the excel format how did you Calculate Bin values and Bin arrays
Glad you\’ve liked the content on Varsity, Ranganath 🙂
Bin values are based on the number of data points. Usually about 25 bins if the data points are between 300-500. No rule though 🙂
Vannakam Guru ,
Very glad to speak to you sir. Little bit confusion about calculation method. I have calculated the normal distribution for nifty last one year period from June 19th 2022 to June 19 2023 with equation of above u have mentioned formulas in MS excel. In your calculation Annual SD ( Annual volatility) is great than Annual Average But i also calculated same formula for last one year returns but I got answers is Annual Avg – 29% & Annual SD – 15%. it seems SD is less than Avg value. This is correct answer or not. For calculate Nifty is likely to be in the range of Average + 1 SD (Upper Range) and Average – 1 SD (Lower Range) \”SD\” is likely to want in Negative value right ? then only we can get lower band value. Pls suggest me how to get exact answer for daily Average / Mean & Daily SD / Volatility.
Sudharsan, how are you calculating the annual average SD? Also, if the returns for a year is negative, then there is a chance for Nifty to goto -ve territory.
Hi,
Recently started reading your modules and find them very interesting and easy to understand. I have one very little query for now, I am trying to get nifty closing prices for last one year in order to calculate Volatility on NSE Website not able to find. However I got the stocks price data on nse website.
Please guide.
Pooja, check here once. https://www.niftyindices.com/
Hello Karthik
I\’m sorry to come back on the same topic.
Firstly, Daily return is different from Daily Average, please comment on this.
Next, as per your example in chapter 17.4 on Daily Average/ Mean =0.04%, there is no clear explanation how is 0.04% deduced. I have cross verified with the Nifty Daily Returns histogram and it results in 0.215% and not 0.04%. Well, I jumped to previous chapters and the example of Billy and Mike makes sense while chapter 17.4 in which Daily Average/Mean is calculated does not explain well.
Can you update this section or explain it in this comment?
Thanks
Varun
Yes, daily return and the average of daily returns are two different numbers.
Lets say your daily returns for 5 days are as follows –
Day 1 – 0.5%
Day 2 – 1.5%
Day 3 – 2.0%
Day 4 – 0.75%
Day 5 – 0.69%
Five-day average return is =
(0.5% + 1.5% + 2% + 0.75% + 0.69%) / 5
=1.08%
Sir,
Could you kindly state if my understanding is correct for the below observations?
1. Daily Volatility of a stock/index = STDEV of past daily annual returns of the stock/index
2. If the above is correct, what should STDEV of past daily annual spot prices of the stock/index identify? can we still calculate the volatility from here?
1) STDEV of past daily returns (not daily)
2) Calculate the daily returns and use the STDEV function on the returns array
The Excel file is not available to download. Please share the same.
Can you try downloading from another browser?
Hey Mr Karthik! I\’m an ACCA student and Im keen to learn about these things.Ill tell u a fun fact,There is a Paper in Professional level of ACCA called AFM which is Advanced Financial Management. There are a few aspects such as Beta,Black sholes Model anol being covered but they were only from the accounting point of view,You are far better than these UK based boards and u indeed simplify topics pretty well .. you are amazing….. My dad use to tell me that the best things in this world are free… I swear that this is the first time I\’m getting it…..
Thanks for that. I appreciate it. I\’m glad you could liked the content on Varsity. And I do agree with what your father says; the best things in life are around us and are indeed free 🙂
Happy learning!
Hmm. Now I got an idea what you mean Sir. Initially I assumed that taking positions early on meant taking the trades slightly before like 2 days earlier for a 4 day SD calculation. But had to say it is quite challenging using SD in hedged strategies since the hedge itself takes away most profits from far out of the money sell positions.
By the way, I\’m currently reading your personal finance and mutual funds module. Your work shows that a non fiction does not necessarily need to be boring. I guess if someone like David Baldacci writes a non fiction it would be analogous to your work. Such a page turner. Please consider publishing books in future and really thank you for helping out slow learners like me.
Thanks for the kind words, Sathish. I hope you continue to enjoy learning on Varsity 🙂 Do let me know if you need any clarifications.
Yes. I totally understand sir. But for instance, if I do the SD calculation for 4 trading days, and try to execute trades early on like 6 days before, although I get fat premiums, won\’t it defeat the purpose of the SD calculation itself?
If you are executing 6 days prior, you need to calculate 6 days SD right?
Thanks for your patience sir. I actually considered that sir. Setting up early on means that the \’time\’ in SD calculation will also increase and so will the number of day\’s standard deviation accordingly. This will in turn increase the range of execution and wont change the profits much since these are very far out of the money. Please correct me if I\’m getting this wrong? This is the problem I faced sir or is it because currently the VIX is ultra low?
Hmm, no. Writing option early means you collect a larger premium owing to heavier time value, right?
If I use SD in hedged strategies like iron Condor(which I mostly use), the rish reward ratio is very poor. Also profits in this case are peanuts. Should I compromise either upper or lower side slightly in this case or how do I approach this?(I\’m asking considering S&R and macroeconomic outcomes)
You can do that, or another alternative is to set up the position early on so that you can benefit from time value.
Hello Sir,
I am a student of your article I don\’t have any idea about stocks after reading all of your chapters and trying out practically in the stock market made me earn more. In this chapter, I just need to know years of historical data needed to calculate mean and standard distribution
Ram, you can start with three years of EOD data. This should suffice, in my opinion.
I am absolutely clear about daily return , SD , Mean
But i am not able to understand how did you get to this ? What is Daily Average
Daily Average / Mean = 0.04%
Daily Standard Deviation / Volatility = 1.046%
Daily average = Mean. The same excel function that I\’ve shown in the chapter helps you calculate the mean.
Your explanations are mind blowing. and too clear .
Glad you liked it, Shubh. Happy learning 🙂
The way all these tutorials are written is SUPERB! There is flow to it which helps in understanding things better. Thank you Zerodha.
Happy learning, Sandeep 🙂
Hi Karthik,
Loved this chapter, for an hour so went back to my school days remembering all those times when Statistics was so fun to learn. Thank you so much for taking your time and taking a step ahead to refresh our basic statistics and relating it to stocks market.
I have a query here, is the statistical way of looking NIFTY important/required when we are looking for intraday opportunities?
With all the crazy global and domestic news happening around (Bank news, war, inflation, recession etc.) I am honestly scared to hold any over night positions in NIFTY.
Can you share what are the things that you consider when taking a trade in options intraday? (Like Price action, technical analysis, indicators, timeframe used, type of news that you consider etc.)
Wanted to hear from you how you do your intraday trade. Hope I am not asking too much, only for learning purpose.
Thank You
It does help to look at Nifty through a statistical lens, irrespective of your holding period, Sai. Yes, I understand the overnight situations can be crazy but that\’s the nature of market. The bottom line is that if you cannot sleep peacefully at night because of an open position, that position is not worth taking, no matter what the expected outcome is.
For intraday, all that matters is how the price action manifests through the day. Keep a close eye on the price development.
Sure. I\’ll start with 5 years data. I previously did with around 13 years data and found that nifty weekly expiring range is between the upper and lower range 9 out 11 times since Jan\’2023. So now I\’ll try with 5 years and maybe try to find if it still fits in. Thanks once again.
Yeah, 13 years data can be a bit dated 🙂
Sir how to find the daily average?
YOu can do it on excel, have shared the steps.
Hello,
I was doing my analysis to learn option trading, so while calculating the standard deviation and the average return for Nifty 50, what should be the ideal size of the dataset, considering it is a daily return. Do we take 20years or 15 years or 10 years of daily return?
Thanks in advance.
I\’d suggest you take 5 years data and slice it down to maybe in 1 year bucket to see how the index has performed. This will be a good starting point.
I am not able to find the way to plot the normal distribution graph.
This entire chapter is about that 🙂
sir if we want to plot a normal distribution graph for any stock or index by ourselves, how should we do it??
I have explained the process in this module itself. You can do it with excel.
Sir I have 2 questions.
1. Why is 252 the time in the case of 1 year calculation and 30 in case of monthly calculation. I thought 252 refers to number of trading days. If so then why number of trading days was not taken in factor for 1 month calculation?(because weekends are holidays)
2. If I had to calculate the same for 1 week, I would be getting only 5 days data since weekends are holidays. In that case, should the time value be 5 or 7?
Thank you.
1) 252 is a day count convention, Sathish. Strictly speaking, if you take 252 days, the number of days should be 22.
2) You can take 5
Sir,
You are calculating from Current market price, if current CMP is all time high the range we calculate comes out to be in the upper side, similarly if current market price is low the range we calculate will be in lower side, both the case results may not be accurate,. Please clarify
Yes, thats possible. Remember, the range is just a predictive tool with some degree of confidence 🙂
hello sir,
I would want to know about the link to the website that you downloaded the nifty daily returns chart. as I am trading in bank nifty and I want to see the daily returns distribution chart.
thank you
Sameer, check exchange website and download the historical data.
Hlo kartik sir
I learnt volatility chapters many time
But I did not come to know how can I use normal distribution curve for trading
. By using the curve how would we decide where to buy and sell
Manish, normal distribution is a concept that will help you understand volatility and trading ranges better. Without an understanding of the normal distribution and its properties, it becomes difficult to figure the associated concepts.
How you have calculated 8337*exponential(26.66%)
By using the exponential function on MS Excel Sohan.
Sir, how do you calculate this?
Upper Range
= 8337 *exponential (42.87%)
= 12800
Even if I add 42.87% on 8337, I get only 11911.
Similarly I dont get the lower range too.
Please clarify the exact method to get the 12800.
Sivakumar, I\’ve explained this in the comments above. Please check.
sir, why are you considering 252 for a year while 30 for a month ? if it is due to nearly 250+ trading day in a year, then why not 21 or 22 for a month? kindly explain.
Thats the right way to deal with the time count convention. 252 is a general convention practise.
Sir very nicely explained, I have never seen explanations of such a critical subject is so easily understandable.
Congratulations and thank you very much for making such a critical subject to make understand so easily.
Happy learning 😉
OK. Thank you. 🙂
Apologies for the repeat question.
Most of the comments with similar questions were hidden by default, so I read them only after I posted my mine.
I wanted to used it in pinescript. I am guessing ta.sma() in pinescript is equivalent to average() in excel.
I\’ve never used pinescript, so cant comment 🙂
> Daily Average / Mean = 0.04%
How is this calculated?
You can use the average function in excel.
Sir, I couldn\’t understand the average return of 0.04%. Could you explain that how you got that figure, or is it just an assumption?
It is just the average of the daily returns, Khitij. Use the \’=avg()\’, function on excel.
Not able to download MS Excel please provide download link to get calculation easy .
Can you try downloading for another browser?
Upper Range
= 8337 *exponential (26.66%)
= 10841
And for lower range –
= 8337 * exponential (-6.95%)
= 7777
Sir here actual calculation come out to be
Upper range = 26.66% of 8337 + 8337 = 10599.6
Lower range = 8337 – 26.66% of 8337 = 7757
Such a huge difference in upper range, please correct me if I am wrong..
Saurabh, we discussed this earlier in the chapter. Can you check the comments once? Thanks.
HI Karthik,
I am trying to calculate the price range of nifty 50 for the past 2 years. I replicated the same procedure mentioned in this chapter. But, the result I got is far away from the actual price for the immediate next year(error percentage of 22~28%). I am not sure if you are following the blog in 2023. But kindly give me reply if you come across this . I can share my excel data over mail.
Thank you
Gopi
Maybe you can share the excel on G drive and share here?
Hello Karthik,
I am unable to download the Excel sheet. Could you please help with that?
Rajesh, can you try downloading from another browser?
How to calculate exponential?
8337*exponential(26.66%)
I am not able to calculate in excel 🙁
You can use this syntax. =8337*exp(26.66%)
Sir,
Under the heading Normal distribution and stock returns Chp 3 ,pg no.10 with the data given.
Nifty CMP 8437 mean 0.04% stdev 1.046%
The calculation given to find upper range and lower range. Given 8337*exponential (26.66%) = 10841 . Sir, please explain the last method used to get the figure 10841
YOu need convert the log returns to a regular scale, hence you use the exponential function, Ajay.
Link to download excel are broken
I guess people can download via different browsers. Can you please try?
Not able to download the excel . How to calculate aver?
Can you try downloading from another browser?
How did ypu plot the Normal Distribution graph? Means X is the change in daily value what it in Y axis
The X-axis represents the percentage change in prices. The normal distribution plots can easily be done on MS excel.
hello sir I need help how did you calculate the average value as i am not able to get the value which you calculated above.
Daily Average / Mean = 0.04%
means nifty\’s daily percentage movemnet divide by total number of days?
am i right????
Yes.
awsome explanation please share your twitter id or any other platform id where you share your views regarding marcket
thankss
Its karthikrangappa on both Twitter and Insta 🙂
Never understood the concept of Normal distribution this clearly. Wonderful and ofcourse the overall explanation was just mind blowing
Glad you found the content useful. Happy learning 🙂
Ok thanks.
Hi Karthik,
For solution 1, I have calculated the Nifty one year range with 1 SD using simple returns(C2-C1/C1) instead of log returns(C2/C1). I got the upper value as 10642 and lower value as 7872 (as against 10841 and 7777). So can i consider these values as more appropriate or is there any reason we should use only log returns.
Yes, Raju.
When a data is not actually normally distributed and it has Skew and Kurtosis, what adjustments I should do while calculating a range so that I can factor in the skew and kurtosis numbers?
Good question, let me check on this and get back.
Thank you for the content , initially i did not get it , but there is a guy called kora reddy .
this guy applies these things and explains much ,after his explanation .
i am able to co relate it.
The assumption that asset prices follow normal distribution can be highly questioned, see for example Mandelbrot (2004) \”The (mis)behaviour of markets : a fractal view of risk, ruin, and reward\”
Prices dont, but we are talking about returns here right?
Solution 1 – (Nifty’s range for next 1 year)
Average = 0.04%
SD = 1.046%
Let us convert this to annualized numbers –
Average = 0.04*252 = 9.66%
SD = 1.046% * Sqrt (252) = 16.61%
&
Solution 2 – (Nifty’s range for next 30 days)
We know the daily mean and SD –
Average = 0.04%
SD = 1.046%
Since we are interested in calculating the range for next 30 days, we need to convert the same for the desired time period –
Average = 0.04% * 30 = 1.15%
SD = 1.046% * sqrt (30) = 5.73%
Dear sir,
please explain how you get the average value of Average = 0.04*252 = 9.66% and Average = 0.04% * 30 = 1.15%.
after calculating the answer is= 0.04%*252= 10.08% &
0.04%*30= 1.20% .
This is little confusing. please explain.
Need to recheck, I hope I\’ve not made any calculation errors.
Tanmoy, I may have inadvertently made a typo here. I need to double-check.
For calculating Annualised SD, why we do: Daily SD * sqrt(time period)?
Because volatility is proportional to sq rt of time.
How can I create the distribution chart in Excel with the data I have? Like the above Nifty Daily Returns distribution chart
I\’ve explained the process. You can use the frequency function for this.
Thanks, Karthik. I fully understood that. However, I was asking about the average ( mean) in absolute terms, that should be constant pivot regardless of you calculating 1SD, 2SD or any more of those varieties. The averages that I got from your calculation ( I calculated it by adding the range numbers and dividing the result by 2) for 1SD and 2SD were different as mentioned in my previous comment. I expected the average to be same, regardless of SD variations, because the mean/average is the constant pivot to find the difference between the distribution values and the mean. Anyways, your write-up is excellent.
The range will change as and when you change the SD, Anant. Happy learning 🙂
Ref: Solution 1 – (Nifty’s range for next 1 year) above: What would be the average (mean) in absolute terms?. From your 1SD calculation above, I get it as 9309 whereas from 2SD cal, I get the mean as 9694?. Can you pls enlighten on this?
So the higher the standard deviation (SD), the higher the range, Anant. Hence, 2SD range will be higher than 1 SD range.
For 95% confidence interval, the values is based in 2 standard deviation but shouldn\’t be 1.96 standard deviation?
For instance:
For 95% confidence level, the upper limit and lower limit should be
Upper Limit: 1.15% + 1.96* 5.73% = 12.3808%
Lower Limit: 1.15% + 1.96* 5.73% = -10.0808%
But, it mentioned that
Upper limit: 1.15% + 2* 5.73% = 12.61%
Lower limit: 1.15% – 2* 5.73% = -10.31%
Which one is correct?
1.96%, 2% is a round off.
Dear sir, I appreciate the method of teaching the calculation of volatility. It is really simple and excellent. In the calculation (In the example of calculation of Nifty range), you have assumed \” Daily average/mean = 0.04. But you have not shown how the daily average / mean of 0.04 is calculated. Please advise how you have arrived daily average /mean of 0.04. Please also advise how to calculate daily average/mean. Please clarify.
d manoharan
There are two steps –
1) Calculate the daily returns of the stock or index you are dealing with
2) Use the excel function \’=Avg()\’, on the returns you have calculated to calculate the average price.
I think I\’ve explained this earlier in this module.
In solution 1 what is the method to calculate average 0.04*252=9.66%
Plz explain how cmp *exponential (x%) is calculated for calculation of price range, and plz also explain how average % is calculated, and how I can calculate volatility for hour time frame or minutes time frame if yes ,how .Will be very thankful
Hey, I\’ve actually posted an extensive explanation for this in earlier comments. Suggest you check that.
Has been and will always be a big fan of yourself and varsity sir. So lucid and simple explanations
Happy learning, Sidharth 🙂
Here you have calculated
Average annuallized = 0.04*252
= 9.66%
But I have multiplied normally but my answer comes out 10.08%
Didn\’t understand your calculation result
How to convert log percentage to regular percentage
By using the exponential function. On excel it is \’=exp()\’. Give the returns within the brackets. Have explained in the chapter.
Sir, why did we use exponential formula instead of straight formula? It would be helpful to understand.
Please scroll up on comments, have explained the logic.
Sir, for the calculation of Upper range (Solution 1 Average + 1SD)
=8337*Exp(26.66%)
=10841
However while calculating this on Excel i got the value to be 10884.10469
The rest of the calculations are good, Can you have a look on this one..?
Ah, possible that this is a typo from my side. Your answer is correct.
sir how did we get that daily average 0.04% and in excel which u shared there is bin array , freq how can we get that values
Dhanush, you can use the =\’Average()\’ function in excel to calculate this.
Sir,
In this context
Upper Range
= 8337 *exponential (26.66%)
= 10841
Instead of solving in this manner, can we solve it by the following way which is discussed in next chapter,
Upper range=8337*(68%+26.66%),
which will be easier.
Sir,Please tell me where I went wrong
Both are alright. I\’ve put an explanation for this in earlier comments. Can you please check that once?
Sir,
How is the daily average given in percentage terms?
Average is a % number, so when you multiply with a number, you do get a % result.
Sir,
For calculating the daily average,are the closing prices of last year till date,been chosen?And also how is the average of daily closing prices of an year converted to percentage terms?
And also 3SD=99.7%,then how probability of black swam or 4SD alone,in this case alone is 0.5%.
And sir last doubt, it\’s a mathematical one,how to calculate 8337 * exponential (-4.58%)
Yes, daily closing price is considered. Also, once you get the average daily return, you can multiply by 252 to get the yearly return. 0.3% actually, not 0.5%. To calculate the exponential value, you can do so in excel.
Hi
I understood that \”Average\” means Daily returns Average.
In case average is (-0.05%) then Lower Range would be higher than Upper range.
Is there any possibility of arriving Average with Minus value.
Please clarify
Ah no, this happens when the stock prices have trended down during the data period you\’ve considered.
Sir in wipro you have calculated daily return and SD
But in nifty you have calculated, daily average / mean.
Have bit confusion about this part sir pls let know
Ah, let me check. Maybe the context is different.
Sir how do we get nifty historical 1years data
Check NSE site, you can download from there.
Hi sir. This is azeesh rahman from Chennai. First of all I would like to congratulate on enlightening me with the concepts of standard deviation and normal distribution.
This may come as a surprise to you, the fact is I am a visually impaired and I studied in one of the premier colleges in India which is located in Chennai. I faced so much difficulties in learning statistical concepts with minimum availability of educational sensitisation to the professors, tools and technologies to teach a visually impaired and a lot more difficulties on my way. I love Maths in my school days and started to hate it in my college just because I am not awarded with the best in class education even in a premier college to learn my favourite subject. But now, with a simple article I am able to understand as well as visualise concepts about normal distribution and standard deviation.
With 99 percentage of confidence in a normal distribution set up, I must say I will score hundred percent in my statistical examinations if it happens today. Anyway I am graduated now. Thank you so much again, you don’t know how much knowledge you have given to me through an article
Azeesh, thanks so much for taking the time to post that message. It really made my day 🙂
I\’m glad you liked the content, and I hope you will continue to enjoy reading on Varsity!
hi sir
i calculated mean value but it got 0.00% for 1 year (took time period was 29-06-2021 to 29-06-2022) nifty50
how much time period we have to take for calculation mean value?
It wont be zero, but near-zero 🙂
hi sir.. how do we get daily mean value for nifty and stocks
Nope, you will have to calculate it.
Hi Sir,
it is really nice explanation on options and greeks. thank you for all your efforts.
could you please share the excel sheets used to calculate Volatility & Normal Distribution ( may be it\’s too late 🙂 I\’m going through these modules, those download links are not working) Than you.
Gopinath, can you try using another browser?
I thank u a lot for providing such valuable knowledge in a simple and charitable way sir
Happy learning 🙂
Is the calculation of average returns / mean just the sum of the ln values divided by their number? I understand and get appropriate values for the Stdev function for calculation of daily volatility, but at times I get negative Daily Average values. Is that normal?
8337 *exponential (12.61%), sir i have not understood this calculation. Please help 🙁
How do you convert log percentage to regular percentage ? Can you explain in little bit more explaination ?
Shubham, I\’have across this and the next chapter. Please do check, also the previous comments please.
You remind me the last chapter of probability in 10th std witch we use to ignore that time….. Now I can understand the value of that chapter….. Thankss u explained in lott simple way
Happy learning, Pankaj!
Sir,
Some questions…
1. While calculating the daily returns of Nifty, you have taken the lookback period from 3/10/2011 till 7/28/2015 which is 5 years.
why have you taken such a long lookback period ?
2. Can we take lookback period to be 1 year only? Will it be sufficient?
Thanks
1) Just to showcase that long term returns are normally distributed
2) Yes, you can.
Thank you so much Karthik sir. Got it.
Sure. Good luck!
Sir, this is referring to section 17.4 – Normal Distribution and stock returns. You have plotted the graph for Nifty returns.
You\’ve calculated the daily average = 0.04% but if we calculate average of these returns it\’s coming to -0.215.
I am taking the returns from the graph that is plotted. -4.17 -3.85 -3.54 -3.22 -2.9 -2.59 -2.27 -1.95 -1.64 -1.32 -1.01 -0.69 -0.37 -0.06 0.26 0.58 0.89 1.21 1.52 1.84 2.16 2.47 2.79 3.11 3.42 3.74. Since i am getting different value I want to know are you using different set of values?
.
The returns that you see are buckets (as explained in the chapter). You need to take the daily returns for this.
Sir can you tell us how you plotted those graphs in excel?? i mean how did you formed that graph?? i mean so we do not have to go through this calculation hassle after plotting this graph i can easily calculate 1sd,2sd in excel just by entering the daily closing price.
YOu can use the STDEV function Vivek. Its fairly easy, I;ve explained in the previous chapters.
Hello Karthik,
Please let me know if \”Daily Average / Mean\” is same as daily return?
where, Daily Return = LN (Ending Price / Beginning Price)
Is Daily Average / Mean calculated the same way?
Yes, that\’s the same thing. The daily mean is the same as the daily average.
Sir, I think the link to the excel sheet is dead, can you please update it…
Hello Sir,
Thank you so much for this amazing content!
I have a question here –
When you calculate this – (I am copying it from your above text) Daily Average / Mean = 0.04% – did you just use = average() and column for average being the % change daily? I am trying to do that and getting very low average, either in +ve or -ve.
I guess I am doing it wrong or something? Because average of absolute % values cant be calculated right?
Thats right. Btw, average returns will be minimal, especially when you run this over large timeframe.
for SD calculation, how much of historical data should one consider?
At least 1 year of data.
Sir,
From where did I get data for preparing Volatility cone.
You can get it from any authorized data vendor (approved by exchange).
Sir for calculation of SD why we sq root 252
hopeing sir gives reply for this. sir, i have calculated range for usd inr using the above used method in nifty. Below i have put a link where i have done the calculation. sir could you please check whether my calculation is correct or not. https://docs.google.com/spreadsheets/d/1zNgU20GBuCu3MsF_yT7526kc8sgFdiKkGfrL_Snq3lA/edit?usp=sharing .
Karthik sir please 🙏 reply .
Sorry, can you repost your query?
sir, i have calculated range for usd inr using the above used method in nifty. Below i have put a link where i have done the calculation. sir could you please check whether my calculation is correct or not. https://docs.google.com/spreadsheets/d/1zNgU20GBuCu3MsF_yT7526kc8sgFdiKkGfrL_Snq3lA/edit?usp=sharing .
Sir, I calculated the range for one month i.e., January. How I get benefit from this range as this range is not achieved in the month of January. what should I do for more accuracy of this range.
YOu can use this range to set stop losses/targets and also identify the option strikes to buy and sell.
Sir, I calculated TITAN range for January 2022 and I taken into consider this data from period 1-1-2021 to 31-12-2021. The range I arrived is not achieved in the month of January, even 99.5% confidence. For what purpose I consider this range like for swing, for option. Pls clarify
It is best for swing positions. Don\’t consider this for intraday movements.
Hello Sir, From the above way I calculate reliance range for 30 days taking period from 17-04-2021 to 16-04-2022 and I took 13-04-2022 closing price as CMP and as per 95% confidence reliance range will be 3136.73 & 2227.88 and as per 99.7% confidence range will be 3416.83 & 2045.24. Is this right can you please check sir ?
Yes, not sure if you got that right. At 99% confidence level the range should be winder compared to the 95%.
I have a doubt on calculating daily average , when we calculate daily average return
we have a year of average return which one daily average data we have to prefer
or how we can calculate the daily average return for the whole year ?
To calculate the daily average, first calculate the daily returns and then run on the daily returns, calculate the daily average.
Hi bro. Could you please tell me how to convert the log percentages to normal percentages.
8337 * exponential (-6.95%) = 7777
Please bro explain the above equation.
I don\’t have enough words to thank you bro.
Thanks for educating.
Prathap, you need to use exponential, like the way you have used 🙂
Hi sir,
Volatility and standard deviation calculations Excel sheet was unable to download from given link above.
Hi sir,
Thank you for easy explanation.
however i am unable to download excel formula sheet you provided, can do it again.
Which excel sheet?
Sir Your way of teaching is excellent…
For one year we need to take square root of 252(as no of trading days in a year)..
And for one month we need to take square root of 30(but not 22 or 21 or 20)..
we don\’t need to count the no of trading days when we are taking about one month calculations..?
Thanks, Gaurav. Yes, if you are considering 252, then take 22 days a month just to be consistent.
hello, karthik Sir
in the example above to find the range of nifty
you picked Mean/Average as0.04%
calculating stansdard Deviation And daily return is fine.
how did you calculate mean from daily return?
Anshul, you can use the =AVG() function in excel. Make sure you use this on the stock returns.
From which website I can get average returns of stocks for past 1 year or 3 months?
In the Graph of Daily Returns what are the values on X=-axis and Y-aixs?
Hi Karthick,
Regarding the below query, u asked me more clarity on this
2.I understand that the NSE’s daily and annual volatility calculation is based on the recent data and also the margins, but can use that value to calculate
the normal distribution
My Query:
In NSE site we have the daily and annual volatility data, can we use that data to calculate the normal distribution(Min and Max range) calculation instead of taking the historical data
Prabhu, I\’m not sure if that can be used for normal distribution. This is something I\’ve not thought about. Need to do my own research. If you find any pointers, please do let me know 🙂
Sir I am novice please do not mind answering my question can daily mean be negative if so what would be calculation
It can be Rajiv, especially when the prices are trending down. The calculation remains the same.
we may use bollinger bands for the same calculations in chart form??
Yup or you can even use ATR.
as the NSE\’s website changed (updated) where can we find the daily & annual volatality ?
Not sure where the NSE has the info now, you will have to google up or check with NSE Shiva.
The hyperlinks u gave this chapter are not working to dowmoad the
MS Excel that u have used to make those calculations..
Dear Karthik,
No one can explain these concepts in a simple manner, thanks a lot for this content
I\’ve few questions below,
1.suppose if writing the options on intraday then I need to use 5 days as the time value
2.I understand that the NSE\’s daily and annual volatility calculation is based on the recent data and also the margins, but can use that value to calculate
the normal distribution
3.And also can I follow the same approach for the option buying also ?
Thanks a lot for your valuable time and the crisp content.
1) Yes, you can use the short term data for intrday purposes
2) Sorry, dint really understand this. Can you kindly elaborate on this query?
3) Need more clarity for the 2nd query 🙂
If a stock have a negative average return than how we calculate the upper and lower possible strikes or how to find an effective range
How long is your trading window? Maybe consider a short-term frame if you are trying swing trade?
Sir the way you explain is phenomenal. Thanks for spreading financial literacy.
please sir explain how you calculate exponential I.e. (8337 *exponential (6.88%)=8930)?
Vibhu, you can use the exponential function in excel to calculate this.
Thanks a lot for confirmation!
Sure, good luck!
Yes!
Then it\’s correct or not?
I got expected ranges for 30 days and lower time frame
Yup, it is.
I calculated the same exercise for TATA STEEL.
Past data range: 03/03/2021 to 02/03/2022 ( 1 trading year)
Tata Steel CMP: 1290
Here is outcome-
Daily avg. return: 0.20% :::::: Annualized avg. returns: 50.40%
Daily volatility: 2.61% :::::: Annualized volatility: 41.45%
Now when I am calculating 1 SD price range for next one year, I am getting results as follows-
Upper range= Annualized avg. return + Annualized volatility = 50.40% + 41.45% = 91.85% (3232.28 in absolute price)
Lower range= Annualized avg. return – Annualized volatility = 50.40% + 41.45% = 8.95% (1410.71 in absolute price)
Here how can my lower range be bigger than CMP? Did I made any calculation errors or is it possible to have lower range to be more than CMP?
Thats because you have a non-zero +ve return right, so it is bound to be higher than CMP.
Hi,
Thanks a lot to you Karthik and your team for the wonderful work you are doing of educating people and making them independent. You people are amazing.
I have a question that average = 0.04 * 252 = 9.66% but when i calculated it comes out as 10.08
and for 30 days it comes out as 1.2 but according yo your calculation it is 1.15%.
Can you please clarify if i am making any mistake.
Hey my bad, maybe I have messed up the calculation. Need to recheck again.
Everything you told was clearly understood.
I tried side by side calculation for current market levels on Nifty bank using past one year closing prices data. All steps done as yours. My daily return average comes to be negative. Is that fine? Like can daily return averages be negative or did I made any mistake? And as daily average returns are negative, annualized average returns are more negative.
Please clarify!
Its possible, but markets have trended up from Feb 2021 to now, right?
In the Above excel sheet link… \”Bin Width\” calculation is not clear…or i don\’t understand… like \”(Max-Min)/50\”… Why 50! I try to research but can\’t find the answer… What i can do in case of individual stock not indexed…What will be the divisor in such cases…
Thanks!
50 is the number of bins, Abhi. I generally go by the thumb rule of 50 bins for 500 data points.
When to convert the log% into normal and when not to?
I have seen you converting log% into normal in this chapter but in the next ones, this % aren\’t converted into normal for deciding the range. Either = CMP (1+%) is used or sometimes just as normal = CMP + (CMP*%)
When to use what?
Can anyone help?
Shreyans, it depends on how you\’ve calculated the daily returns. If you\’ve calculated using simple returns, then no need for any conversion, but if you\’ve calculated using long returns, then yes, you will have to convert it using the exponential function.
Karthik Sir, how to convert log % to normal cant understand this one sir!!
You use the exponential funtion. I have explained it in this chapter.
Karthik Sir, the bollinger ball concept is also based on normal distribution crt sir?
Yup, it is.
Can you please help me how to re create the nifty histogram, I tried my histogram looks anything but normal distribution, it would be really helpful. Pls
Nick, did you follow the step-by-step instruction that I have shared in the chapter? If yes, then you won\’t miss getting this histogram.
Don\’t think zerodha will allow writing strike that far, will try with 2 sd
Sure, good luck Ankit.
Hi Karthik, can I use normal distribution to write weekly options also, and what should be the historic period for calculation purpose?
You can use Ankit, but keep the limits to 3SD 🙂
Good evening sir,
I calcutate the Nifty 50 from 18 jan 2021- 20 jan 2022
Average=16218
Mean= Sum of( Daily change of the nifty on previous day basis / no. of observation)
=13.9028
How can the
Daily average / Mean be calcuated in % form Sir
Please explain sir
Ujjwal, to calculate the mean, you first need to calculate the daily returns. Once you do, use the average function of the daily returns.
Thanks Karthik for your prompt response.
I guess when you have to draft so much, small mistakes can happen, nevertheless your study material is really worth the time and I would like to give you thumbs up for your effort, after all, altruists are pretty hard to come by these days.
I wish you well.
Thanks, Jason. Happy reading 🙂
The excerpt from the chapter is somewhat confusing
\”Daily Average / Mean = 0.04%\”
\”Daily Standard Deviation / Volatility = 1.046%\”
Question 1)
The \”/\” (forward slash) in the above statements, do they mean \”or\” or \”Division\”?
e.g.
1) Daily Average or Mean
2) Daily Average /(divided by) Mean
We are dealing with equations here and these statements almost have me confused because of that \”/\” (forward slash).
Question 2)
e.g.,
Number series: 11, 10, 12, 14, 10
Daily Return =
LN(10/11) = -0.04139
LN(12/10) = 0.07918
LN(14/12) = 0.06694
LN(10/14) = -0.14612
from the above example if I take an Average of Daily Return my result is negative -0.010348171 or -1.035%
however, if I \”square\” each daily return i.e.,
(-0.04139)^2 = 0.00171
(0.07918)^2 = 0.00627
(0.06694)^2 = 0.00448
(-0.14612)^2 = 0.02135
then my Average is positive 0.00845 or 0.845%, but here the average becomes Daily Variance.
What average should I take A) Average of Daily Return or Average of Daily Variance?
Please revert soon if possible.
Jason, you are right. Probably I should not have added the forward slash, now that you mentioned, I guess its confusing enough 🙂 But yeah, Daily Average/Mean —> Average or mean and not division.
Daily return and variance are two different things. If you want to know what is the average return of the stock, then stick to the average daily return. But you want to figure the risk, then you need to variance and then the standard deviation.
Hi Karthik,
I am going through all these chapters and all are well written. Loved the way you have written all chapters, very simple and understandable. Thanks for all your efforts!!
I have one doubt. How did you calculate average here? I am talking about — Daily Average / Mean = 0.04%
Thanks for the kind words, Digambar. I\’m really glad you liked the content here. For average, I used the excel function \’=Avg()\’.
Hi Sir,
I could not calculate 8337*exponential(26.66) in calculator. It is giving very long number.
If you don\’t mind, can you please elaborate this on calculator?
Regards,
Pavan.
Pavan, try MS Excel.
Sir I am grateful to you for providing such a good content in a most simple manner Sir i have two doubts
First how to select width of a bin and number of bins what is logic behind it.
Second you have taken 30 days for calculating monthly range why not 22 as in case of yearly you have used 252 instead of 365.
Yash, roughly 25 bins for 500 data points. There is no rule as such, but this is something I like to follow. You need to select the date convection, if it\’s 22, then ensure you take 252 days. If 30, then 365. Idea is to be consistent with the selection.
Thanks for this beautiful presentation. In the last 30days we saw large swing in nifty movement and daily average return i found is 0.237% (if i am not wrong) which is high and considering 1SD limit ,nifty future on expiry is worked out as 18288 (upper side) and lower side is 16774. Upper side figure seems to be unrealistic. If nifty moves wildly , expected range would be more from current value on expiry. If you write option beyond this range then premium would be very very low specially on call side. Am i wrong Sir?
You are right, with markets trending, the average increases and the range expands. And yes, the further you move away from 1SD, the lower is the premium. The only way to deal with it is to write these options early in the cycle.
Sie
What is on the x and y axis of the normal distribution curve when we are talking about the stocks
X-axis – returns
Y-axis – Number of of observations
Hi Sir..Nice explanation but not able to download excel.
Let me check on this.
sir, for monthly nifty range cal. why we multiply it with sq. rt 30 ? should it ne sq.rt 22 or 23 ?
Jimmy, you can take the actual number of days i.e. 22.
Hi Sir,
I Gone through this Chapter and Next chapter also…
I have questions-
Instead of Prediction with this Mathematic – Can we Apply Fibbo tool for Same Result?
1) if I need weekly Prediction Data – I Can apply Fibb on Daily Time frame from Last day to Untill 6 days. Is this possible ?
2) same like 1 day Prediction need, then apply Fibb only two days data.
Pls Tell me is this Possible ?
Yes, you can, although I\’ve never tried since I personally prefer the math based predictive models.
Hi @karthik I didn\’t understand below line
= 8337 * exponential (-6.95%)
= 7777
Can you plss explain me how you did exponential of -6.95% .Did you use exponential function F(x)=a to the power x where a!=1 and a>0.
Plss help me I am stuck here
Swarup, you can do this in excel easily. Yes, I used the exponential function in excel.
I didn\’t understand this part
= 8337 * exponential (-4.58%)
= 7963
What is exponential .Is it f(x)=a to the power x where a!=1 and a>0 ?
Can you help elaborate me .M stucked here.
Sir, Why we have converted the log return into regular return??
What\’s the difference between log return and regular return??
Have explained that in the comments already, Shubham. Request you to check that once. Thanks.
how to calculate daily average / Mean of a stock?
Have explained the procedure in the chapter itself, Pradip.
The order in which the explanation is done so that we won\’t get struck confused in next topic and the way of explanation in simple words so that everyone can understand is much appreciated. And, all this for free of cost. For which people are charging in lakhs. For this i am really grateful to u. Everyone should be. Thanks alot.
Thanks for the kind words, Sandeep. I hope you continue to like the content on Varsity 🙂
Sir, why have you used daily returns of so many years in the excel sheet?
How many days return should we us3 for calculation range for a year?
Amit, you only need to calculate it once. YOu can use the data for the last 1 year.
I really appreciate if someone can proved the nifty example excel file. The download link does not works any more.
Dear Sir,
Thanks for sharing your knowledge. I had one doubt why you choose date range from 10/03/2011 to 28/07/2015 – Excel data (4 Yrs & 4 Mths). Because last chapter we took only past 365 days only. If we need more than 1 year means why you select from 4 yrs back is there any reason to took from that date range. If I want to use this method to calculate NIFTY range for Comming 30 days or Next 1 year means what past historical date i need to collect. Please clarify me Sir.! Thank You
You can select 1-year data to do this as well. Once you do, you can convert it to a rage that you are working with. For example, convert 1 year data by dividing the data by sqrt of time i.e. 30 days.
Sir how to create nifty 50 or individual stocks return distribution chart in one calender year or my own time period? How to create mean std deviation, average etc. as you shown in above chart. Pl inform asap.
Pravin, I\’ve explained most of these things in the chapter itself.
My intelligence starts to question something and you (sometimes I sense as GOD) start answering them before I begin to ask question. I feel like Deja vu. I have no doubts, I am just taking you as a person to be admired and look up to, if I had to teach something to someone. My benchmark is to exceed you. A big Thank you, Stay blessed!
Hey Vasant, thanks so much for the kind words. Words like these encourage me and my team to do better 🙂
Karthik Sir,
Good morning. Thanks a lot for such a valuable information in this chapter. I am excited to go through the writeup regarding calculation of 1SD and 2SD range for future specific number of days. One clarification I wanted. Whether we have to consider one year data for arriving at the daily return or last 30 days data is sufficient. I got this doubt because I calculated the Nifty 50 range using the method you depicted considering 252 trading days as follows and I got the below figures.
1. Daily average / Mean = 0.15%
2. Std. deviation = 1.03
3. Average for 45 days = 0.15% * 45 = 6.83%
4. Std. deviation for 45 days = 01.03*SQRT(45) = 6.89%
5. Upper level percentage = 6.83% + 6.89% = 13.72 %
6. Lower level percentage = 6.83% – 6.89% = -0.06%
Nifty 50 Spot is at 16680
7. Upper range of nifty 50 = 16680*exponential(13.72%) = 19133
8. Lower range of nifty 50 = 16680*exponential(-0.06%) = 16669
Sir, my doubt is whether these figures can be taken for statistical analysis. The lower of the range is almost at the current spot value. So I had a doubt about this. Is it because the nifty 50 has run up so high. Or we can consider lesser number of days (say 30 or 60 days) for calculating the daily average and standard deviation.
Sir, hope you will kindly evaluate this when ever you have time and clarify my doubt. I am totally confused.
Warm regards.
Premakumar Kootagal Sanjeevaiah.
This is because Nifty has trended quite a bit over the last year. I\’d suggest you increase the time frame to 2-3 years here.
Sir
The average of 0.04 is fixed or variable for other stocks , if variable how would we have to arrive that value
No, it varies from stock to stock. Have described the details in the chapter itself.
Hi Sir , I am unable to download the MS excel sheet that u have mentioned at the last . Can u please help me out by providing the link ?
Can you try and download from a different browser?
Yes definitely later on i just figure out that i can use MS excel.
Good luck!
Sir this may sound silly but would you like to help me. I don\’t know how to convert log percentage to regular percentage. I even searched on internet i just got confused. i have a scientific calculator but i just dont understand this exponential and terms like that. Thank you so much your content is really helpful and interactive.
Bhavya, I\’m not too familiar with the scientific calculator. But you can use the \’=exp()\’ function in excel for this.
Really you are a great teacher,thanks for everything and I have a doubt ,I know how to calculate the sd but how do you calculate average in percentage if we just have the closing data.
Like I mentioned, you first need to calculate the daily return using the closing price. Daily return will be in percentage anyway.
Really you are a great teacher,thanks for everything and I have a doubt how do you calculate average in percentage if we just have 2 year data.
When you calculate the average of returns, the result is in percentage anyway.
Please tell in details about the other volatile benchmark known as VIX
Its already discussed in detail here.
Like you said 252 days in a year and 22 days in a month, will it be more accurate to consider 5 trading days in a week for calculating min-max range of option price in weekly expiry.
I think 5*52 minus holidays is roughly 252.
sir, how to extract daily average / mean as you did in nifty chart as 0.4
Calculate the daily returns and apply the =\’average()\’ function in excel.
HI,
can you explain how avg of daily return% is converted to yearly as the calculation mentioned is 0.04%* 252 = 9.66% but isn\’t it 10.08%??.
The reason i thought for mentioning 9.66% is due to log function involved but i\’m not sure…can you clarify thanks
Srikanth, I need to recheck this. It is 10.08%, but not sure if I\’m missing something here.
Sir, you have calculated the BIN width ?? what is it ?? Can you plz share some thoughts on it..
No particular logic for bin width. I take about 25 bins for every 250-500 data points.
Dear sir,
plz share the excel sheet for calculating the Volatility which is shared in the Following chapters.
Chapter 16:- Volatility Calculation (Pg No:- 153)
Chapter 17:- Volatility and Normal Distribution (Pg No:-166)
You can download it here on the chapter page.
First of all
Amazing content!
Doubt – Why are we always using data of 365 days to predict everything (range for next 1 year or next 30 days)?
Any logic or significance?
365 is 1 trading year, which gives you a sense of what the yearly daily average is.
Hai brother, actually I have done normal distribution of 1 year price of Wipro, I got upper of 116.98% and lower of 50.79% the lower is not the negative value is it correct or the lower value must me negative or not?
Ex: 1 year 1 SD, CMP – 561.70
UPPER = 116.98% – 1809
LOWER = 50.79% – 933
lower value is higher than current market price is it wrong or correct ? can you help me brother please !
Need not be negative, depends on how the stock has trended.
We cannot download ms excel of calculation. plz resolve it.
Did you try looking at another browser? If not, please try that once. Thanks.
SIR LINK TO DOWNLOAD EXCEL SHEET NOT WORKING PEASE HELP
Sir,
While calculating sd and mean of a stock, what if sd is greater than mean?
Does that mean my calculation is incorrect or something else?
It usually does. YOu\’d need to recheck the calculations.
Hi Karthik,
Perhaps I did not word my question concisely. The data you pulled from NSE for 2014-2015 was correct and so also the calculations. I used the average rate of return and SD from this data to forecast upper and lower range for 2015-2016. I then looked at the actual range. Actual range was very much narrower than the forecasted one.
I kind of also seeing that in CadillaH stock too but have to confirm it yet. So I am asking myself if I want to know range for next 5 days or 10 days or x days, should I use the same time frame for calculation or longer time frame or?
Lastly I hope it is fine to continue to ask questions to you. I just got into this few months back and it is only now that I am reading the varsity notes. It is perfectly fine if you do not reply immediately.
Sathya, thanks, this gives me more clarity. Range is an estimate, perhaps you should test this across few more instruments to get a sense of how you can tweak this to apply it. You can use the last 1 year data and estimate the daily volatility and extrapolate it to whichever time frame. Its absolutely ok to do that.
Please do feel free to ask your queries without any hesitation, this forum is meant for that 🙂
Hi Karthik,
I will post another related question so that you can answer both: I invested in CadilaH futures yesterday. I did the following:
1. Took last one year data, did the math and transposed it for 5 days which is my planned holding period
2. I repeated the above taking last 6 months data, last 1 months data and last 15 days data.
3. I have now got the forecasted range for the next 5 days for the above four. Now I will see what happens actually.
4. I have also derived the SL from the 5 X SD method. Let me see how actually it behaves
5. The main problem in using one year historical data is that during that time period, the stock nearly doubled and so the rate of return is very high. So I am not sure if using it NOW for my short-term swing trade is correct. But on the other hand I believe that higher the time-frame, greater the significance. Any suggestions on this?
Since I had traded in futures, I have to download futures historical data right? I see that NSE does provide that. Can I use that?
Thanks a ton!
Your procedure and its interpretation seem right. Yes, the higher the time frame, the better is the significance. Yes, you need to look at the futures (or even the spot) data for this. If you are using the spot, you place the SL/Fut mentally on spot but operate the futures.
Hi Karthik,
I used the average return and volatility calculated for Wipro (from your previous chapter) for 22.07.2014 to 21.07.2015 and used the distribution method (from this chapter) to calculate/predict likely range for period 22.07.2015 to 21.07.2016 (succeeding year). I got the range as 752 and 471. But when I looked at the NSE historical data, Wipro was, for a few times, in low 600s but normally in the 500s but never went to 700s or 400s.
My calculation could be wrong but if not, is there a logical reason for this? I verified that there was neither bonus share nor share split during this time period.
Ah, I\’m not sure Sathya. I must have pulled off the data from NSE. Maybe a special dividend or something?
n continuation of the previous question and your reply I just want to clear my doubt on why below here you have not taken AVERAGE for finding annual range in your example:
Before I wrap this chapter, let’s make some prediction –
Today’s Date = 15th July 2015
Nifty Spot = 8547
Nifty Volatility = 16.5%
TCS Spot = 2585
TCS Volatility = 27%
Given this information, can you predict the likely range within which Nifty and TCS will trade 1 year from now?
Of course we can, let us put the numbers to good use –
Asset Lower Estimate Upper Estimate
Nifty 8547 – (16.5% * 8547) = 7136 8547 + (16.5% * 8547) = 9957
TCS 2585 – (27% * 2585) = 1887 2585 + (27% * 2585) = 3282
So the above calculations suggest that in the next 1 year, given Nifty’s volatility, Nifty is likely to trade anywhere between 7136 and 9957 with all values in between having the varying probability of occurrence.
The percentages expressed is annual, Shova.
Hi Karthik,
In continuation of the previous query, I wanted to continue with one more query at this time:
(6) You have given us the two methods of calculation of range – one is with the example of Billy and Mike and another one is the by using the historical methods i.e. Average, SD, etc… Which one to use for options trading and other tradings?
Average and SD.
Hi Karthik,
(1) You have taken the data of 4 years in the excel sheet for Nifty. Why is that so?
(2) The range for the calculation of which all the exercise is required to be done, is for the options for how much duration?
(3) What was the purpose of calculating daily, yearly and also 30 days in your excel sheet and why not specific to the number of days for which we need to calculate the range?
(4) In the replies to many of our sisters and brothers above, you have mentioned that period of 1 year, 1.5 year or 2 year is good. What is the basis of choosing the number of years for the calculations?
(5) The range which we are calculating here, is only for the options or can it also be used for futures, commodities, currency and regular equity market?
1) I cannot recollect why, but I guess to incorporate longish data points which covers bull and bear cycles
2) Sorry, dint get that.
3) This is is done with the intention of identifying the possible range within which the index will expire and hence selecting the appropriate strikes to write
4) You dont want to select a data period where the stock was continuously going up or down. Include a wider range to have market cycles.
5) All
Hello Sir,
Explanations are top notch!!!
Have one question, How to calculate Daily Average / Mean ? Did you sum of Daily return/number of days ?
Please let me know.
Thanks
Kumar, you can do this easily on excel. Calculate the daily returns and then take the average of it. I guess we have discussed this (or the previous) chapter.
sir, why you have multiplied the average with no of day for calculating range. It increases the range. Can we use only SD and multiplied it with closing price to get range
Like = clsoing +- 1*SD*SQRT(252) to get 1SD annual range
Like = clsoing +- 2*SD*SQRT(252) to get 2SD annual range
Below you multiplied average with no of days
Average = 0.04*252 = 9.66%
SD = 1.046% * Sqrt (252) = 16.61%
So with 68% confidence I can say that the value of Nifty is likely to be in the range of –
= Average + 1 SD (Upper Range) and Average – 1 SD (Lower Range)
= 9.66% + 16.61% = 26.66%
= 9.66% – 16.61% = -6.95%
No Shova, thats not possible 🙂
Hi Karthik,
If we do the calculation without taking the LN the daily avg would be 1%, then that means for 252 days it will become 252%. The SD is the same ie 16.61%. If we continue the calculation like this end result would be different from what you have calculated. Please let me know whether I have gone wrong somewhere.
Volatility is proportional to the Square root of time, Anish. You cant consider 252 and linearly multiply it.
Thanks 🙂
No need to explain the mathematical equation, just a formula on excel will do. Thanks again.
Here is the excel formula –
=8337*EXP(26.66%)
Hi Karthik
Thank for the quick response.
I wanted to download excel sheet because I wanted to know how did you convert log percentage to normal percentage.
Note these % are log percentages (as we have calculated this on log daily returns), so we need to convert these back to regular %, we can do that directly and get the range value (w.r.t to Nifty’s CMP of 8337) –
Upper Range
= 8337 *exponential (26.66%)
= 10841
Can you please help me here?
I\’ll be happy to help, but which step are you missing?
Hi Karthik
Not able to download the excel sheet. The link just does not open. (No error shown).
Also do you think after completing this module + option strategy module + technical analysis module, I should be able to trade in actual market. or should I take any paid courses or do you recommend any book?
Thank you for the content though… its wonderful!!
Please don\’t take a paid course 🙂
After these modules, you should be able to trade the markets, if not for anything you should be able to navigate comfortably. Make few small trades based on your own logic and see how it goes and build on it.
I\’ll check on the excel sheet.
Dear Karthik,
Average = 0.04*252 = 9.66% – Please explain, I didn\’t understand the calculation.
Daily average return multiplied by the number of trading days.
Hi,
I am not able to download your excel file?
What error are you getting?
How do we convert log returns to exponential returns. Please Help
Have discussed the same in the chapter right?
not able to download the excel working sheet
Why exponential is used to calculate range?
To convert log to regular scale.
sir, Daily Average / Mean = 0.04% for nifty
how did you calculate sir??
I\’ve explained this in the chapter itself, including the calculation method.
Hi Karthik,
I have newly started analyzing the data, reading through your chapters. Can you please let me know where can I get the NIFTY data downloaded as when I click on NSE1 link from earlier chapter or from (https://www1.nseindia.com/products/content/derivatives/equities/historical_fo.htm). This is asking for fields which are very specific like what Nifty option 50 or Fin Nifty etc and specific expiry date as mandatory field. So when I try to extract such data, can;t see valuable data but mostly 0 in underlying value or strike price. Could you help me with steps to download right data for Nifty so that I can try with SD/range predictions?
Ah they have changed the layout. Maybe you should check with someone from NSE itself, they will be of better help.
You\’ve made a 1000 years lasting content, THANKS! But I have few doubt and I\’m unable to move ahead without clearing those doubts, please help.
DOUBT 1
If you do this calculation
9.66% (Average) + 26.66%(1SD)(Upper range)
=26.66% (but when I calculated answer is 26.27%. Why and how? (However this is not that important but still a doubt))
DOUBT 2
To convert log % to normal percentage you\’ve said, \”We can do that directly and get range value (W.R.T to Nifty\’s Current Market Price of 8337.)\”
So my question is what is W.R.T??
FOLLOWING 2ND DOUBT
DOUBT 3
Upper range= 8337(CMP) * exponential (26.66%)
=10841
What is exponential? And how did you derive it?
Because when I calculated
8337* (26.66) total was 2222.64.
So why your answer is 10,841 and my total is 2222.64?
If I add
8337+ 26.66% = 10,559.64(close but still different from your total)
Thanks Mr. Rangappa in advance. Your content is really changing lives of people who are eager to learn what school or college did not teach them. ❤️
1) Not sure about this, Anish. Need to check
2) WRT is a short form for With respect to 🙂
3) Exponential is a constant, more on that here https://en.wikipedia.org/wiki/Exponential_function , we do that when we need to convert log to regular form
Thanks for all the kind words, happy learning!
Dear Sir,
Do you take historical volatility to be yearly or quarterly as a reference?
Yearly, Suhas.
Hello sir,
Sure I can do that.
But how does one predict that Stock X\’s IV will increase in the future or not and when to take action on that?
So if today\’s vol is lower compared to historical, then one can expect it to increase. Likewise, if the volatility is high.
Sir,
In many of your option strategies etc you have mentioned to enter a trade if IV is going to increase etc.
But how does one know if IV will increase? apart from results and certain monetary policies how exactly can one say that X stock volatility will increase/decrease in the coming days?
You can compare current volatility with historical volatility and figure if today\’s volatility is high or not.
How the daily average value of 0.04% is calculated?
Have explained that in the chapter itself.
Dear Sir,
Could you care to explain a method of writing a naked call option 1 SD away when there are 3-5 days till expiry.
I followed your exact method mentioned in the module, yet I generally have a situation where my stop loss gets triggered.
The idea is that there is 66% chance that the underlying will stay within 1SD. If you want a higher degree of confidence, maybe you should consider 2 SD.
How do I find the daily volatility for non f/o stocks instead of manually plugging data into excel everyday? I would like to set volatility stop losses?
ATR or Bollinger bands? Btw, I remember NSE publishing this data on their site long back, I\’m not sure if they still do.
Hello Sir,
I agree to maintain hedged positions is the only way to avoid gaps.
But let\’s say I write weekly nifty options 3-4 days away and 1 SD away.
Maintain a hedge option is nearly pointless as I would earn roughly 2 points(150) on a margin of roughly 30-40K.
Is there no other method to write options 1 SD away?
You can find methods, but the issue is gaps. Its very hard to avoid them without hedging it away.
To Follow up with my previous question.
What exactly can I do to avoid gap up/gap down when I short positions 1 SD away when there are 3-4 days before expiry?
What kind of stop loss can I maintain?
It is very hard to avoid gaps. The only way is to maintain a hedged position, but hedging comes with its own set of restrictions.
Dear Sir,
A couple of questions.
A) Zerodha has a GTT system where I could set up trigger stop-loss prices to exit my position. However these are only active during market hours correct.
Lets say I write an weekly nifty option on Friday for 6 points and set a trigger stop loss of 9 and 10. (trigger at 9, SL of 10) points. Now on Monday Nifty pre open gaps up and my option opens at 14 points during market hours. My trigger price will not get triggered and I will continue to lose a large amount. What can be done about this? Is there a better way to put a stop loss?
B) How do I find the daily volatility for non f/o stocks instead of manually plugging data into excel everyday? I would like to set volatility stop losses. Or should one use ATR? However ATR does not account for SD ranges hence I am not much of a fan.
C)
1) Nothing can be done about this. All orders are valid only during market hours, not off-market hours. It is like wanting to buy a shirt when the shop is closed, that\’s not possible, right?
2) Yes, ATR is a great alternative.
SIR,
Can you please share the formula used to calculate average. because i am getting much higher value
I\’ve used the \’=Average\’ function in excel to calculate the average.
Sir, Can you explain how to convert log percentage to regular percentage?
Multiply it with the exponential factor. I must have included an example in the chapter.
sir, if we have the premium to lose in call buyer option then what does stoploss work for?
YOu can cut your losses here as well. For example, if you write an option at 60, you can square off the position at say 55 or 40 or any other amount. No need to wait till expiry or wait to lose the entire 100.
hello Karthik, So can we say that if a stock moves let\’s say to its 2nd or 3rd SD in a single move so can we say that there is a high probability that the stock may have exhausted its move in one go and may have higher chances of coming down??
Not really, although there is a fair amount of possibility.
delta, gama, theta and volatility etc are very complicated terms but you have described all of these in such a way with day to day example that even a novice can learn all this very easily. Thanks a lot for making a tough subject very easy.
Happy learning, Vipin!
i had a doubt about converting log returns into normal returns like how do we do thiis exponential thing?
Have explained this in the chapter itself right, Raghav.
Thank you Karthik. In case if you come across, pls let me know.
Will do. Good luck!
Hello Karthik, Hope you are doing good.
I started using the chart setup \” Value Lines\” which is very useful. Thanks for the good learning, i wouldn\’t aware of SD if i haven\’t go through varsity. Value lines clearly gives the boundaries and easy to identify strike price especially for option writing.
Quick question, do you know how much of past/trend data is used to arrive those values? (for EOD SD\’s i normally use 1-1.5 year data, In Zerodha chart i use 5 Mins, just curious to know how the values are arrived )
Thanks in advance.
Regards,
Harsha Gp
Harsha, I\’m not really familiar with Value lines myself, need to check that 🙂
Got it, someone had asked about this a few days back:)
You replied about using 25 for every 500 data points
Thanks
Yup, I remember doing that 🙂
Thank you very much for this article, very well explained and you make it so easy to understand!!
In the formula to calculate bucket range, why do we divide by 50? Is this selected randomly or is there a connection to the data set?
Thanks in advance
Ajay
Ajay, usually the bucket size is 25 for every 500 data points. No hard science here, just an approximation.
Hi Karthik,
Two questions,
(From Chapter 16 – Volatility Calculation (Historical))
1. What is the difference between using the Log returns or the other way shown. Is one way better than the other?
In this video from you guys, https://www.youtube.com/watch?v=IrSZBgFCf00&t=1603s&ab_channel=ZerodhaOnline, at the 19.14 mark, you didn\’t use log returns so that\’s why I was confused.
(From this chapter)
2. How are you putting this into your calculator because I am having trouble getting the right answer,
= 8337 *exponential (26.66%)
= 10841
Im confused about the \”*exponential (26.66)\”.
Thank you for this whole website, take care,
Ankit
1) For a short date range, like 1 or 1.5 yrs, regular will do. For more than that, please use log returns
2) Use excel for this.
Hello Sir,
Where exactly have you mentioned this on the risk module sir?
There must be a way to minimize the loss such a situation from happening correct?
Why cannot my stop loss order get carried onto the next day? why is it only a daily stop loss order?
You can place a long-standing SL via a GTT order – https://zerodha.com/z-connect/tradezerodha/kite/introducing-gtt-good-till-triggered-orders
Hii Sir,
So on Friday 09/04/21 before close I had written nifty 13950 PE for 6.25. This was little over 2 SD away and Nifty closed at 1485
I had initiated this position as I knee nifty has been rangebound since a while and there were only 3 days till expiry (Wednesday 14/04/21) was a holiday. Expected time to work in my favor and easily pocket 6.25 points per lot.
Now Monday 12/04/21 my premium value shoots up to 28 on opening. This reaches a high of 48 and closes at 38.
I exited my position at 30 during the day.
I ended up losing 5 times what I had expected to gain haha.
No problem, any tips on what I should do to avoid such a thing? Like these huge gap ups and gap downs??
What kind of stop loss should I put for writing options? Note I had written a naked option and not a spread as I had written the option 2 SDs away not near ATM. If I would have written near ATM I would have initated a spread.
Ah, sorry for that. These things are unavoidable. The trick is to control risk and expose capital wisely to each trade. We have some content around this topic in the risk management module.
To follow up from my earlier questions.
1) If you are writing options for a longer time frame maybe more than 1-2 months away than one could use annual returns right?
If you are writing monthly or weekly/biweekly index options one should use past 2-3 months annual returns correct?
2) Writing options 2 SD away generally result in only 8-10 points. But to see a huge 1500 point which completely destroys the your option that you have written. Is there any stop loss strategy you suggest or do we just choose a fixed amount as a SL.
3) Doubt cleared.
4) But If I am writing options with past 3-4 days till expiry you had mentioned that it is better to write naked options. Writing a spread reduces the premium from 8-10 points to like 2-3 and reduces the RR also.
1) That\’s right. Idea is to pay more attention to recent volatility
2) YOu can choose to have a fixed SL like 10% of the option premium
4) Reduces premiums and stress 🙂
I may be among the \”late comers\”- as I have just started stock \”marketing\”😉 but I must say You are an amazing \”GuRu\”; explained the things at its best..! Thanks.
One query what the Y axis represents In daily return charts of indices and stock showing normal distribution..
Eager to read next chapter.
THANK YOU.
Happy to that, Sachin 🙂
Y-axis represents the number of observations.
Hello Sir,
1) So for writing options it is best to look at past 3 months data? Each month has roughly 21 trading days so past 62 days data??
Basically data per quarter correct??
2) If I were to write 1.5 SD or 2.5 SD. That means the underlying would move to 2.5 SD and my stop loss would trigger. But in the meantime the option price would increase substantially which would result in massive losses for this same move towards 2 SD.
By trying to earn 8-10 points I would end up losing upwards of 50-80 points. Very confused about this.
3) I will try this with top 10 stocks.
4) What can one do account for gaps? BankNifty gapped down 800 points today and 1500 points overall. I paper traded and using annual returns I wrote banknifty 29400 pe ( This was 2 SD away). Bank nifty has not yet reached that point, but my option price has moved from 10 to 80 points. Now I can just hope that bank nifty does not breach 29000 pe in the next coming days otherwise I would theoretically lose a lot of money.
What could I have done in such a situation?
Thank you for taking your valuable time to answer my doubts sir
1) Yes, but its a good idea to keep track of the last 3/6/12 months data in perspective
2) Agreed, hence the need to choose trades which make sense from the risk and reward perspective.
3) Sure
4) Yup, this is something that cant be avoided. For this reason, most professional traders prefer spreads rather than naked option strategies.
Namaste Sir,
I have a few questions if you can answer them it would be great.
1) When writing options using daily returns and volatility. Do you use annual returns/ past 2 year returns or something like 6 month returns or a shorter time frame??
For example nifty annual has grown 80% but past month has dropped and during march 2020 it dropped by a large quantity. What reference point should one us.
2) Let say I write options 1 or 2 SD away. What should be my stop loss? How do I go about working on this?
3) For writing stock options, it is very hard to get a liquid 1 SD away stock option and 2SD is nearly impossible. Which means we could only do it on nifty/banknifty. However, nifty and bank nifty are very volatile compared to stock options and often gap up and gap down. What should one do?
4) How do you address gap up/gap downs for nifty bank nifty. As the moment it happens, it is sometimes difficult to place a stop loss as market already opens 200 points down/up.
Please assist me if possible sir.
Thank you
1) I\’d look at the recent volatility, something like the last 3 months
2) If its 2SD, then something like 2.5 SD can be your SL
3) Have you tried this with the liquid stock option? By liquid, I mean the top 10 stocks
4) It not possible to account for these as gaps are quite random.
HI,
Lovely and very insightful read.
In chapter 17 on volatility, there is an example for calculating nifty range where annualised mean = 0.04% x 252 = 9.66%. I am unable to follow how you arrived at this calculation as 0.04% x 252 = 10.08%
Also. the file for download where you have worked out the calculations…. the average of LN (previous day close/present day close) is taken over multiple years….. shouldnt it be for the period we are calculation i.e 365 days.
In Solution 2 of the same example…. the Average = 0.04% * 30 = 1.15%….. but the calculation is 1.20%. Also, while finding the movement over next 30 days (I\’m presuming one month and not 30 trading days)… shouldn\’t the square root of time for calculating SD be 22 days? As per your solution…SD = 1.046% * sqrt (30) = 5.73%
Same thing in the next chapter
16 day average = Daily Avg * 16
= 0.04% * 16 = 0.65%
But mathematically the calculation should be 0.64%.
Would appreciate an explanation. Thank you in anticipation.
Kishore, thanks for pointing these out.
1) Yes, I think there is a typo. Don\’t know how I missed this
2) Yes, it should be for the last 1 year, not all data series, only then it will be consistent
3) 22 or 30 is fine, based on the time count convention that you want to follow
Sigh! don\’t know how I missed all this and no one pointed it over these yrs 🙂
sir can you give any excels regarding this values
Daily Average / Mean = 0.04%
Daily Standard Deviation / Volatility = 1.046%
The excel function is quite straightforward –
For average it is =average()
For Std Dev it is =Stdev()
Hello Karthik Sir! Great explanation.
But I am confused about these calculations:
\”Remember to calculate these values we need to calculate the log daily returns.
Daily Average / Mean = 0.04%
Daily Standard Deviation / Volatility = 1.046%\”
Please can you help me with that? My calculations aren\’t matching yours. Maybe, because I am inserting wrong values.
I\’m not sure where you are going wrong, Harshal.
17.3- In normal distribution
how this values came & how to calculate
Daily Average / Mean = 0.04%
Daily Standard Deviation / Volatility = 1.046%
Sujith, have explained that in the chapter itself.
Hi Karthik,
This is some pretty nice material – thank you so much!!
I have one question: in \”Nifty_Example.xlsx\” how do you arrive at a bin array size of 51?
I apologize if it\’s something quite obvious.
(It wouldn\’t be the approx. # of months from march 2011 – july 2015, would it?).
Kind regards Jonathan
Jonathan, this is an approximation that I use, 25 bins for every 500 data points, since there are 1000 data points, 50 bins.
I Confused to geting this value
Daily Average / Mean = 0.04%
Daily Standard Deviation / Volatility = 1.046%
can u plz explain with examples
and excel download option could\’t work
WHich part is confusing Sujith?
Hello Karthik,
That seems plausible.
But for example keeping a stoploss like that could result me in existing my position at a substantial high premium loss?
Would you mind giving an example of what you have mentioned?
Would you use an ATR for option charts??
Thats right, but the probability of SL triggering is also low. Dont have an example on top of my head. ATR for options, hmm, I\’m not sure.
Hello Sir,
Let\’s say I have written Nifty 15600 options for Rs. 8 and pocketed Rs.8 per lot.
Suddenly NIfty starts to make some serious upmoves.
How exactly should I keep a stop loss as due to the upmoves the premium rises to 22.
I mean just hoping to wait it out and hope that NIfty closes under 15600 is just wishful thinking. So there be a better way on what I should do?
Viren, one thing that you can do is to keep the SL based on the underlying price movement. For example, you write the option when Nifty was at a certain level, you wait for it to go against you by x% and at that point, you place an SL and exit.
Dear Karthik.
Entire march, nifty/bank nifty has had negative returns which results in a negative daily return.
Overall the daily return is positive if you calculate from annual basis.
You get different nifty/bank nifty ranges if you use different returns.
So which should be used to get a. more accurate understanding?
Also lets say I used the annual returns to find nifty 2 SD range till 15500. Anything above 15500 has a 5% change of reaching till expiry.
Now Nifty increases by 1%, consequently the new 2SD range becomes 16000.
What does one do in this situation? Do you range your trade ?
Viren, stick to daily data for at least 1 year period. Yes, 1% move will change things. Hence for this purpose, at any given point you fix on the range and act based on that, else this will be a daily moving affair.
Hi,
I tried to calculate for SBIN and difference of values are high when compare to NSE site for both Daily & Annual volatility.
I am calculating for 2nd April 2020 to 1st April 2021.
Daily Volatile is 2.60%
Annula is 40.95% if considered 249 as number of sessions ( total number of close price availble from the report)
Where as NSE for script is showing Daily as 2.73 and Annually 52.7.
Which needs to be considered as final results will be different which may impact accuracy of strike selection.
Pl advise.
NSE calculates the volatility slightly differently, I guess they give more weight to recent data (factor lambda) since they want to calculate volatility wrt margins.
Hello Sir,
So my issue is that if you use annual nifty returns you get a daily return of 0.28%.
If you use march 21 returns that are negative results in a negative daily return.
Both of these have a result in a significantly different range.
So which exactly should one use?
I did calculate daily vol and scaled it up by multiplying sqrt of time.
You need to take the yearly returns right? Why are you taking it only till March 21?
Hello Sir,
I hope you are doing well.
I have done some calculations for finding the range of Nifty from 31/03/21 close to 08/04/21.
CMP Trading Days till Expiry Annual Return (%) Daily Return (%) Return till Expiry
14690 5 70.87 0.281230159 1.406150794
Annual Vol (%) Daily Vol (%) Vol Till Exp(%)
28.36 1.786512076 3.994762444
1SD Upper Range Lower Range UPPER RANGE((1SD,5 days) LOWER RANGE(1SD,5 days)
3.994762444 0.054009132 0.025886117 15483.4 14309.7
Upper Lower Upper(2SD) Lower(2SD)
0.108018265 0.051772233 16276.8 13929.5
Here I used the 1 year annual Return, calculated daily return by dividing annual return by 252 days.
Annual Vol I determined to be 28.36, daily vol was (annual vol/ sqrt(252)).
Are these calculations correct?
I repeated these calculations for April 15th expiry, note there are only 10 trading days
CMP Trading Days till Expiry Annual Return (%) Daily Return (%) Return till Expiry
14690 10 70.87 0.281230159 2.812301587
Annual Vol (%) Daily Vol (%) Vol Till Exp(%)
28.36 1.786512076 5.649447227
1SD Upper Range Lower Range UPPER RANGE((1SD,10 days) LOWER RANGE(1SD,10 days)
5.649447227 0.084617488 0.028371456 15933 14273.2
Upper Range Lower Range UPPER RANGE((2SD,10 days) LOWER RANGE(2SD,10 days)
0.169234976 0.056742913 17176.1 13856.4
Nifty has been range bound past 1 month.
I feel even If I use the calculations to write put options 2 SD away after 10 days I still have a very large chance to lose money.
What should one do?
Do I calculate my daily return from using the monthly daily return?
Viren, you can calculate the daily vol and then scale that to the period you are interested in by multiplying it by Sqrt of time right? Besides Nifty in a range must be a good thing for writing options right? The outcome is more predictable.
What a nice tutorial. Best thing is that you care for economics as well as science background readers!
Nice Job.
Happy reading and learning 🙂
Sir I am not able to download the excel file for volatality and normal distribution through your link given in the chapter.Can you please send it to me to my email ID.
Seems to be working, can you try from a different browser please?
Hi,
Very nice and detailed explanation for using std deviation and mean to predict prices.
The formula is for 68% confidence level
mean + 1sd upper limit
mean – 1 sd lower limit
How will the formula change if the mean is negative or remain the same.
Thank You in Advance
Rane, in that case we will get -ve values of the range, not very helpful I guess 🙂
\”\”\” Do note, an average of 0.04% indicates that the daily returns of nifty are centered at 0.04%. \”\”\”
The above lines are from the chapter 17. Please explain how to calculate above value.
Please use the average function in Excel to calculate the average.
Dear Sir,
Everything is well explained with examples, but still I am not getting how you calculated \”Daily Mean/Avg of NIFTY\”, which is Daily Average / Mean = 0.04%,
Can you please elaborate further??
Thanks in Advance
Purvil, I just mean to say daily mean (or average), it is not a division sign 🙂
Hi,
Which technique should we use to calculate the range out of the two – the EXP one or (1+ / 1-) one in general.
1. As this range technique works on stocks n Indices whose returns are in Bell Curve . How to ascertain , whether a stock of Index’s returns are bell shaped or not . N if it is not bell shaped this technique won’t work.. Am I right
2. From where do I get USD INR Futures data for last 1 year . Everywhere they have USD INR data only.
3. can you suggest any Good Book or course to learn in depth about
ForecastVolatility GARCH(1,1) (1,2)
1) Stock return are normally distributed, but prices aren\’t.
2) The data you see is for the futures I guess
3) I\’m not sure, but maybe you should check on few Quant trading forums.
Sir,
For calculating volatility its mentioned as
CMP * Exponential(Up Range%) = 8337*EXPonential(26.66%)= 10841
However on my excel sheet when I inputted =8337*EXP(26.66%) it’s giving me answer as 10884.1. Is there anything incorrect I have used .
2. Moving ahead in Chapter 18.1 you have calculated the range differently
It is 8462*(1+1.4215%) = 8818 , instead 8462*Exponential(1.4215%). Both of these gives different results..
Its just a rounding issue, otherwise its the same result. The 2nd query, its another technique.
Where do I get the information of Standard Deviation, Variance, and Mean for the last year? I can calculate the mean but where do I fetch the variance to calculate the rest of the values.
You can calculate all these things easily on excel, have described the way to do that as well.
how to execute the following in excel :
Upper Range
= 8337 *exponential (26.66%)
= 10841
I tried 8337*expo(26.66) but result were different .
Expo is not a defied function, use EX instead.
Hello Sir,
Could I just use the Bollinger band to calculate 1-2 SD from the current price and write options from there?
Standard bollinger band is 2 SD, I can make it 1 SD and us those prices as strike prices?
Yes, thats possible.
Dear Karthik Sir,
For annualized volatility, you use 252 days( number of trading days in a month)
For weekly you use 5 days (no of trading days in a week)
Monthly you use ~21 days.
Assuming I am calculating volatility till expiry for this month (Feb 25/02/21)
There are 19 days till expiry as today is 06/02/21.
But there are 14 trading days.
To calculate SD, do I use 19 days or 14 days?
Should I apply this same logic to calculating Future Fair value pricing/Option B&S Price calculator?
14 days will be fine, Janta.
Dear Karthik, I am very late entry to all this stuff, but better late than never. Its really amazing that Maths / Stats play such a pivotal role in trading. Had I knew it in childhood, I would have for sure focused more on it. Thanks a ton to you Karthik for bringing out these explanations. I mean, I am kind of stuck still as I do not know how to thank you, as any appreciation I do, would be very minimal to stature of the content you presented here !! Still, Thank You dear Karthik.
I have a very basic question here – the Daily Average or the LN derived in previous chapter \”Volatility Calculation Historical\”
These numbers are negative for few days. Now, while calculating range should we use absolute value of this LN or use the LN as is ?
Because the exponential value of positive and negative of same absolute numbers are different.
Would be helpful to me in case if you could clear the air on this question.
Once again thanks a lot Karthik for this wonderful Varsity Course..
Best Regards
Ajay
Thanks for the kind words, Ajay. This means a lot to me and the team 🙂
You need to use the value as is, and not really leave out the algebraic sign.
Hi Karthik,
Bollinger Bands give us 3sd….does that imply that I can use BB ranges as SD ranges for finding out probable range of Nifty for the coming 5 days with a 98% accuracy?
Yes, you can use BB for SD. The confidence level is 95% I think.
In calculating SD for annualized volatality why we r takung square root on 252
That\’s the way to scale volatility across time. I guess this article may help – https://financetrain.com/time-scaling-of-volatility/
Hi Sir,
Excel file is not getting downloaded you uploaded in this chapter.
Checking on that.
Hi Sir,
How did you calculate the average i.e. 0.04%?
Did you add the daily return of 252 days and then divided it by 252?
I did the same calculation for TCS Data from 20Jan 2020 to 21st Jan 2021 and my daily average is .16% and the annual average is 39.44% but my annual SD is coming at 35.64%.
Ankit, I used the \’average=()\’ function on Excel.
Hi. The doubt is regarding for calculating weekly expiry range.
For conversion of daily volatility to weekly volatility, how many days i have to represent in the formula(i.e, 5 or 7) for weekly expiry???
For weekly, please consider Sqrt of 5.
Hi Karthik,
First of all, thanks a ton for sharing this valuable knowledge with everyone. It was really hard to find where to start learning before I found Varsity.
I just wanted to confirm if my analysis and understanding is correct about volatility as I don\’t feel confident that the results are correct. I\’m calculating Nifty 50 range for 1 year (3rd Jan 2020 – 1st Jan 2021) and I get below ranges for 68% (Lower – 9556.95774 Upper – 18480.04226), for 95% (Lower – 5095.41548 Upper – 22941.58452) and 99% (Lower – 633.8732207 Upper – 27403.12678).
Daily volatility – 2.004856046
Annual Volatility – 31.82610308
Please validate if these values are correct.
Sravan, unfortunately, I cannot validate this, but this seems like realistic values to me.
Hi Karthik,
Thanks a ton for sharing the knowledge, I wish you all the success.
A quick question on converting log percentile to normal percentile to identify the Range volume i.e. upper limit and lower limit.
You have used Exponential method, can we also use normal percentile method as well or using exponential method is the best ?
Thank you !
If you calculated the returns using log method, then the exponential way would help. Else, you can stick to the normal method.
Hey Karthik, beautiful explanation. I was wondering how can we hedge our positions when we short options 2SD away? Should we apply a positional trend following system, can you give some examples of the same? Or simply what would be an optimal way to hedge the position as one black swan event can destroy the entire capital. Or is the best option is simply to stay away from puts and short only calls?
The best bet is to buy a further OTM PE option 🙂
How to calculate \”Daily Average/Mean = 0.04%\”. please
You can use the excel function, \’=average()\’ for this.
Sir,
No need of clarifying my doubt again. I could get it through the beautiful explanation of our friend, Purab.
Thank you very much, Purab…
Happy to note that 🙂
Hi,
Thank you for such a lucid explanation
I just wanted to understand things better hence wondering why we use SQRT and EXPONENTIAL functions in our calculation, rest all make sense to me
Like I mentioned, thats the math involved Mahesh.
Sir,
You have a wonderful technique of teaching tough things in an easy way. But one thing is not clear to me. That is nothing but changing a log % into a regular % manually. Please explain it.
8337X Exponential(6.88%) =8930…here the value of 6.88% is(8930/8337)0.01071128703370 %….But how….????…..Based on the answer I have got it …Please explain it
You need to do this when you consider log returns, as in use the exponential calculation to convert to regular %. Have explained the same in few comments earlier.
Average = 0.04% * 30 = 1.15%
How can this be 1.15%?
Here we are calculating monthly expected return using the daily avg return, assuming there are 30 days in a month.
Hi Karthik,
Is Daily Return, Average avg/mean are the same ? If so, are we using daily return only to calculate SD? and we need to calculate daily avg separately ?
In the previous chapter, you did not mention about daily avg but you did mention about daily return! And now, in this chapter, you are not considering daily return but daily avg!
Please help me to understand
Regards
Vijay
Average daily return anyway comes from the daily return right?
Thankyou Kartik for solving my query, also I really like the way you respond to people and solve their doubts.
Another question I have is, Suppose there are 2 weeks left for the monthly expiry and I were to short option which I know would expire worthlessly, then how much historical data do I need, Is there any kind of requirement like at least 6 months or anything else?
Happy to note that, Hetang 🙂
You need to look for at least 1-year data to get a perspective.
do we have to check for a particular % being repeated in the daily return table and the % that has been repeated the most is our average right?
No, not at all. You just calculate based on the real returns.
Hello Kartik, I have gone through the last chapter and also this chapter and also got to know that the bin with the most number of balls is taken as average and then we have to calculate SD based on it. But I didn\’t really get how you got the Average part in the nifty example!
I\’ve calculated the average returns on excel, Hetang.
Where can I find the excel sheet to calculate stock/nifty SD
Search for \’Download\’ option on the page.
Hi,
Credit goes to you for the understanding I have gained so far. Interesting way of explaining a complex topic like Options Trading.
Right from Arun and Venu\’s example to the Normal Distribution, it had been a great experience.
Please advise how do you calculate bin width. I noticed you took 50 as the no.
Thanks, Sonal. I\’m glad you liked the content. I took 50 since the number of data points was large, I\’d take 25 if it was lesser. It is basically dependent on your assessment of the data size, no rules here.
how do you get nifty average 0.04%?
I used the average function on Excel.
Thank you so much Purab and Karthik sir! I understand this concept much better, now. Grateful for your responses:)
Happy reading and learning, Aarti 🙂
As far as I can recall, Exponential (26.66%) would mean, e ^ x, where e = Euler\’s Number (2.71828) and x = 26.66% or 26.66/100 or 0.2666.
So,
8337 * exponential (26.66%)
= 8337 * [e ^ (26.66/100)]
= 8337 * [2.71828 ^ 0.2666]
= 8337 * 1.3055181
= 10884.10
Similarly,
8337 * exponential (-6.95%)
= 8337 * [e ^ (-6.95%)]
= 8337 * [2.71828 ^ (-0.0695)]
= 8337 * 0.93286
= 7777.2549
This is the correct explanation of the calculation I suppose. Mr Karthik?
Thats correct, Purab.
\”Note these % are log percentages (as we have calculated this on log daily returns), so we need to convert these back to regular %, we can do that directly and get the range value (w.r.t to Nifty’s CMP of 8337) –
Upper Range
= 8337 *exponential (26.66%)
= 10841
And for lower range –
= 8337 * exponential (-6.95%)
= 7777\”
Sir am simply unable to understand what is happening in this stage of the process. I do understand that exponential(e) is the inverse of \’ln\’ from my 12th std. math class(and its being used in the excel sheet you provided as a function to arrive at the range). But then how we are using it here to calculate the upper and lower bounds is just difficult for me to digest; does not come very intuitively to me, to say the least. As in why can\’t we keep it simple like we did for TCS and nifty in the previous lesson (100-27)% to (100+27)% to arrive at the range.
May be am unable to explain my doubt. But from whatever you understand, I will be glad if you could help me a bit.
Many thanks sir.
These are two different ways of doing the same thing, Aarti. This happens when you take log returns.
Karthik Sir,
How is the SD calculated? I come from a non-mathematics background. Which function is to be used on the calculator to calculate the exponential?
YOu can use the \’STDEV\’ function on excel.
How many days\’ data should we use to find SD, or how long should the look back period of daily returns be for calculating SD? Is it different if we want to calculate the SD for the next month and next week?
I\’d suggest you look for at least 1 year of data. For short term requirements, I\’d say 6 months.
Hello Sir,
I really love the way you explain the concept. Just have a small doubt does the concept evenly applies to currency option, and what happens when your daily returns comes to negative should we increase our sample size or just ignore the scrip.
thanks in advance
Yup, the concept applies to all options. -ve prices can be a problem, yes, you probably need to increase the sample size.
Hello Kartik.
My question is are there any good online websites or applications which can calculate volatility? If there are any, how accurate are they?
Thanks.
Do check out Sensibull – https://sensibull.com/
Sir,
Can you please explain how \’log percentages\’ are converted to \’normal percentages\’? What is the calculation behind, \”exponential (26.66)\” as in what calculation is done on 26.66? I am a bit weak in maths but I really want to learn this.
Thank you in advance sir.
The standard exponential function is applied to convert these numbers, Tavleen.
Hi Karthik
Thanks for taking me back to my school days where i hated Maths/Stats. My interst picked up from Delta chapter. Very interesting and informative. will take time to sink in and i feel one reading is not enough.I am unable to download the excel file. Says it is a protected file. Can you please help me out with this .
Thanks
Happy to note that 🙂
Lets me check on the excel file.
hi karthik,
based on these STANDARD DEVIATION calculations ,it was mathematically proven that price follows a curve kind of formation.
For example if we watch Nifty 50 price chart right from inception , it always makes rising line with higher highs & highers lows(including 2000,2008 stock market crashes).How can SD be applied in that scenario. please explain.
Please forgive if question is meaningless.
Ajay, the returns follow the normal distribution pattern, but the prices don\’t. Prices do trend to trend.
Hi, What if the Average value turns out to be negative?. My BN average is -0.11%, so for lower bound how do you arrive at the Figures assuming BN SPot is at 22320 and SD is 2.68%
Its a problem if we have a -ve value. Try increasing the lookback period to 2 years or more, also ensure you are taking log returns.
Thanks a lot Karthik. Noted your suggestion.
I am trying to post a query (may be bit lengthy) for the past couple of days but for some reason its not getting posted here.
Is there any way i can reach out to you pls?
its related to getting your insight to do reverse engineering on a strategy which is being successful. As per backtest data it is successful, but trying to understand the logic behind it pls.
You can post it either here or tag me on tradingqna and I\’ll respond.
Hello Karthik, thank you for being generous to respond all the queries.
Have a quick questions, I realized there is a reasonable difference between nifty volatility as per our historical calculation and the one available in NSE. I think it is IV and calculation is based on options. Is my understanding correct?
For the weekly positional trade, i wanted to derive the volatility. What would you suggest, go by historical or take NSE VIX and divide with SQRT(365), then multiply with 5?. Thanks in advance
Yes, thats right, our calculation and the one on NSE is different. NSE\’s volatility calculation is mainly from the margin\’s perspective and it is weighted heavily on the recent data. I\’d suggest you take the volatility calculation from our method. Good luck!
what if is we calculate range on a daily basis and how can we find avg returns if i want to calculate suppose a week range?
You can calculate the range on a daily basis, works for intraday trades. Weekly avg is the avg return * 5.
hello sir,
sir is it possible that the daily mean/average is greater than SD ?
Unlikely.
Wow, what a coincidence..!! This Exact topic of Normal Distribution was going today morning in My CA Final costing Class..!!😄
Nice! I hope this will help you understand the concept 🙂
Hello sir ,
the process of calculating through excel is a lenghty process , is there any way to capture the same data elsewhere ?
Rajat, do check out Sensibull.com for this.
Alright, I got the idea. Thank you for your response.
Good luck!
What is the ideal duration of historic data to calculate the daily return and standard deviation? If we use last one year of data, the standard deviation will be much lower than that with last 6 months of data. How does one select the duration? Will it be different depending on the intended application? Thank you!
The best way is to ensure that your data has both bull and bear cycles so that the behaviour of the stock is captured in both these cycles. Keeping this in mind, I\’d say 1 or 1.5 years worth of data is decent to get started.
Nassim Taleb isn\’t going to like how you explained black swan events.
Not sure what to make of that, care to elaborate?
is it also used to calculate the Support and Resistance of Indices and Stocks? It seems so.
I\’m not sure about this, Sanjeev.
Hi,
Are stock returns always normally distributed ?. If not, which formula should be used for detecting the range of stock.
Stock returns are, prices aren\’t.
sir ,
Can we directly add or minus volatility % which is given on nse website to the spot (nifty ) without considering avg % to get range ?
ex. spot = 10772
volatility =1.88%
upper range =10772+1.88% = 10974
lower range =10772 – 1.88% = 10569
for tomorrows range .
Yup, you can.
hey kartik,
thanks for the content
Btw you could have simply used excel forecast for predicting the range rather than all these tiresome calculation.
Hmm, maybe. But the idea was to explain a few concepts along the way.
Sorry, I thought it as division
Ok, happy reading!
How have you calculated this fig:
Daily std deviation/volatility
In last chapter, it\’s said volatility aka SD
Is it that volatility for curve refers to 1SD ?
Yes, when we talk about volatility, it usually refers to 1SD.
okay sir thank you .
Welcome!
Sir i calculated the log returns but still it is showing negative values for mean ,infact i had put values in your excel sheet which you provided in the course ,in that also it is showing negative values. thank you
Vishal, has the stock trended down continuously? If yes, the returns will show -ve.
hi sir ,as i was going through the calculations of wipro ltd i am getting a negative mean of daily , weekly and monthly.And when i am applying those value to find an upper and lower range for 1 year it is showing negative numbers for both upper -6% and lower – 84% .
I\’d suggest you calculate the log returns, Vishal.
Helpful, will try and read up on VIX
2. Also when u say daily mean is (0.04%) and when you say annualized mean is 0.04% *Sqrt(365) how is this different from daily compounding and annualized compounding in interest rate. I am just a little confused if the 2 work in same fashion
The difference is in the math, volatility is proportional to the sq root of time. Please don\’t ask me the math behind, I\’m not good at that 🙂
Thanks that helps understand.
Also when we say VIX it means a plot of the daily SDev of the nifty day closing over what period of time ?
Aditya, vix is the implied volatility of ATM strike. Not sure about the context of SDEV here.
Firstly very well articulated chapters and it just keeps me glued wanting to read more. Options simplified !
Had a query around the calculation. Plz let me know if my understanding is right
Stock Maruti
Mean – Daily (-0.089%), 30 day (-0.49%)
Std Dev – Daily (3.13%), 30 day (17.12)
Now say i am calculating range for 30 day @ confidence level 2
SD 2 – 5000 * Exponential (-0.49% +2*17.12) = 5831 upper band
SD 2 – 5000 * Exponential (-0.49% – 2*17.12) = 3263 lower band
Am I going right in the calculation considering the mean is negative value ?
Yes, this is correct.
Hi Sir
Please Correct me if i am worng
1.) I am very much confused by this 2 calculations in this chapter
Average = 0.04*252 = 9.66% { we do the same in calculator (10.08)}
SD = 1.046% * Sqrt (252) = 16.61% {we do the same in calculator(25.31)}
2.) And
when we are calculating range for next one year why is reason we are using 252
(is it because we are exclude Sundays and Saturdays )
And
when we are calculating range for 30 days why is reason we are using 30 days itself
Please correct me if i am wrong somewhere
Waiting for the response
Thanks Sir
Regards
1) 0.04*252 = 10.08 is correct, the other one is 16.61%
2) 252 = number of trading sessions. If you are sticking to 252, then monthly you should stick to 22.
Dear Sir,
It seems that Standard Deviation calculation of Normal distribution is not working in BANKNIFTY from the last two weeks.
As BANKNIFTY is very Bullish and increasing 1000 to 1200 points in a week. Selling Bank Nifty is not a wise step at the present situation. What should be the strategy now can you please suggest.
You need to deep OTM calls, but that will be a risky affair given the momentum. Maybe you should consider buying opportunities 🙂
Hi Karthik,
When I calculated Mean(average) for last one year\’s daily returns of nifty I am getting a negative value (eg. -0.12%), so is there a condition that mean should always be positive value..or have I gone wrong in my calculation…please guide me.
Waiting for your response..
Shabarish.
Negative values is possible given the crash in the market. Dont think you\’ve gone wrong in your steps 🙂
Good Day,
Thank you so much for this amazing content!
Just wanted to know, being a long term investor (3-5 years) approx, is it okay to gauge the risk by considering weekly avg. returns instead of daily returns?? or will it cause too much change in the confidence levels ??
Weekly is fine, Ronak. You can go ahead with that.
1. daily mean is daily volatility?
if no then how to calculate daily mean using excel?
No, they are different. Use the average formula to calculate the mean.
so can I use the black sholes formula and as implied volatility is the reverse engineering process also if I use\” goal seek\” a formula to determine the volatility and then compare it with historical volatility and see if the given strike is expensive/cheap?
Yup, you can.
as we can calculate the daily return and daily volatility. this is will also help us to find annualized volatility.
what if I want to calculate the 52wk high and 52wk low volatility of the stock/Index.
India VIX gives us low and high for nifty. Is there any way to find out the same for stock.
so that I can compare the Historical Volatility and Implied Volatility to find the right strike.
I\’m afraid historical high/low of vol is not easily available.
hie sir,
sorry for bothering you again and again,
1. how did you calculate daily mean which is 0.4% ?
2. I was calculating daily volatility of reliance share , It was something 0.02344 like there was so much numbers after point, how did you get that in percentage ?
1) Daily mean is the average calculated over the daily return time series
2) If you are using excel, then click on the % sign, it will convert.
ok
Sir,
In that case, which one to refer ? difference with NSE data is more than double.
I know, please give me some time and I\’ll figure this out.
so you mean to say that if i calculalte volatility for nifty then i should take date of last 1 year and caculate sd and this sd will be relevat for upcoming 1 year.
Hmm, frankly I don\’t know at this point. Doing my research on it.
sir , i want to know that why u selected 1 year period for calculation of sd and average return. Why u didn\’t take 2years or any number of years or months and for what future period is this sd and average return is relevant.
1 year is a good starting point 🙂
Sir,
Thanks for elaborate & informative study materials. I want a clarification regarding daily & annual volatility calculation. I used same excel sheet in the chapter 17 (nifty caln). I checked for nifty & many other f&o stocks. Daily volatility comes <2 roughly & annual around 25%-30%. But in nseindia site, it shows huge difference , for daily ~3.5-3.8 , annual vol. ~ 66% to 75%. Even after changing no of days from 252 to 365, only 4 to 5% difference. but nowhere near the figures shown in NSE site. I feel my calculations seems to be correct. I have only copy pasted one year data with date, for nifty & various stocks. Pl help.
https://www1.nseindia.com/live_market/dynaContent/live_watch/get_quote/GetQuoteFO.jsp?underlying=NIFTY&instrument=FUTIDX&type=-&strike=-&expiry=28MAY2020
I\’m aware of this difference. NSE calculates this slightly differently, they calculate the previous day;s vol and kind of extrapolate the values. They may be doing this keeping the margins in perspective.
Hello sir,
Great journey so far, lockdown can\’t be better than this.
I have a small query, the avg returns are their in terms of logs. Sometimes we are changing it to normal and in the next chapter, we are not. Can you state the logic behind it. Also what is the best formula for returns, is it the log one or the normal one?
Use the log returns, Pranav 🙂 I was just trying to showcase different methods.
Sir ,
There is a posting on September 21, 2017 at 11:53 am User Says :
I’m also facing the same problem while trying to change the FREQ formula in H14. The current formula is =FREQUENCY(E9:E1096,G14:G64). Now my data range has changed in col E, so I need to change that. When I’m trying the same, it is giving the error message – “You can not change the part of an array”. Can you please look into this?
TO WHICH YOU REPLIED :
Are you sure you are selecting the right date range? Also do pay attention to the Çtrl+shift+enter thing when using the frequency function.
So i am Also Trying to re Create the Work sheet But facing the same problem ( Please Clarify the Following Points ) :
a) . I am Unable to keep Cell numbers constant Actually it should be =FREQUENCY(B10:B274,D10:D60) but as i Drag the Formula it becomes =FREQUENCY(B11:B276,D12:D62) ….. =FREQUENCY(B59:B324,D60:D110) where am I Going Wrong ? .
b). in my Excel Sheet Frequency is all ZERO – 0 no other number . Why is it so , what is wrong with me ?
a) Try locking the cells with $
b) The excel issues will be very hard for me to solve, suggest you look up for videos online to check how -Frequency() function is used in its right syntax
I am surprised to see that stock returns follow a normal distribution.
Food for thought: It would be interesting to see what kind of distribution does trader\’s earnings follow. Would it be somewhat normal distribution (or heavily skewed that most traders make loss/profit), or some other distribution altogether? Perhaps if Zerodha has such kind of data of its users, it would be an interesting exercise.
I don\’t think we can do that as a broker 🙂
Hello Karthick,
Firstly thank you for posting these chapters and indeed its of great help for novice like me.
My Query: How to determine IV (Implied volatility) for Banknifty ? In the chapter you discussed on calculation of historical volatility using excel and then determining the Strike price. In my understanding, in order to determine the correct strike price, we would need IV and HV and then determine a +1 -1 SD range and decide on a strike.
Please if you can share the process of
a) Determine the IV
b) How to consider the IV and HV and then come out with a % that can be applied to determine upper limit and lower limit for the Normal distribution
Thank you in advance.
1) You can use the B&S calculator to identify the IV, check this – https://zerodha.com/z-connect/queries/stock-and-fo-queries/option-greeks/how-to-use-the-option-calculator
2) This is explained in the chapter itself no, Anurag?
Respected Sir,
Namaste, In the graphs plotted representing the normal distribution of daily average returns for Nifty, Bank Nifty, TCS, Cipla etc, Y-axis represents daily average . What does the X-axis represents which is scaling from 0 to 100 or 120. Kindly explain please. (Though I am not a statistics student, I could understand all other concepts explaned so far. Thanks a tonne for your methodology of teaching which can be understood even by a lay man sir.)
Y axis is the number of observations and X axis is the % return.
I could never really understand normal distribution or for that matter, most of the things taught in Prob & Stats back in college.
If only things could be taught the way you do, they can be made much easier and fun to learn.
Thanks Karthik 🙂
Happy learning, Rohit 🙂
Sir
In Solution 1(Nifty\’s range for 1 year) above, its written 0.04*252 = 9.66% but actually it comes out to be 10.08%.
Thanks
Sir
Volatility implies RISK associated with a stock. Once we have the volatility data, we are trying to compute the range within which stock / index can go viz. UP or DOWN. By computing this range, aren\’t we looking at the UPs and DOWNs of the stock / index ? So volatility means ups and downs of the stock / index but we are calling it as RISK. Kindly correct me if I am wrong.
Thanks
Fair enough, another way of looking at risk 🙂
sir ,how to find daily return average of nifty ? i tried finding the historical data of nifty index but it shows calls and puts data ! how to find nifty spot historical data?
Please download the historical closing prices of the index and calculate the returns and then use the average function on excel to get the average returns of Nifty.
in the second solution you have directly calculated 30 day standard deviation without using SQRT ,i.e std.dev = 1.046%*30 but you have calculated all others using SQRT ! which one should I consider ?
It is Sqrt of time. Not sure if I missed this.
@karthikrangappa in the first solution , why did u calcualted standard deviation as daily vol*sqrt(242) ? why dint you calculate as *sqrt(364) as you mentioned previously?
@karthikrangappa sir , can daily average be calculated as the mean of daily returns ?
Mean and average is the same no?
Hi Karthik,
Thanks for putting out such wonderful content to understand trading.
I was trying to calculate daily volatility for last 1 year starting from 09 Apr 2020 in excel and my Daily SD came as 1.8 %. In NSE website daily volatility is showing at 4.7. Why such big variance?
Birsha, please check the previous comments.
Dear sir,
Thanks for putting such a valuable information here. I have a query regarding the calculations of upper range and lower range of stock value based on average and standard deviation. Question is as follows:
What if the average daily return value is negative? It is just an average of all the daily returns of (say 1 year data).
How will be the upper and lower values in such a case? I have done a calculation for a share price for last one year and found the average value as negative. After that the upper and lower bound values looks absurd.
Regards,
Prasad
-ve values can be tricky. Happens when the stock has continuously trended down. Probably like a Yes Bank. The calculation technique remains the same.
sir I understood everything but only have one doubt that what is the daily average or mean is it the average of daily volatility %or something else please sir kindly reply I need your help
Avg can be on anything, returns in this case.
Hi Karthik ,
The Excel Worksheet has words like \” Bin Width \” , \” Bin Array \”, \” Frequency \” , Have you explained these on this Article ? where is this explained . i m missing to understand these . Please point me to the article where you have explained these .
Ah, I\’m not sure if I have explained this separately. I must have done this contextually in the flow itself. Let me also recheck.
Hello Karthik
First of all thank you for writing these articles in a lucid manner. Really appreciate it.
I have a query though.
When you annualise daily return you multiply by 252 (I assume we excluded the days when markets are closed). However when calculating daily return for 30 days you did not exclude the non-working days (Saturdays & Sundays) before multiplying. Doesn\’t this create inconsistency in the returns calculations?
[…] 17. Volatility & Normal Distribution […]
In the chapter about \”Volatility & Normal Distributions you explain
Converting Upper and Lower Range Log Returns to Simple Returns as \” Spot * exponential( Average + SD)
and in the very next chapter “Volatility Applications” you explain the same conversion as \”Spot * ( 1 + (Average + SD)) and Spot * ( 1 – (Average + SD)) for upper and lower range respectively.
Can you please explain why this difference. Thou I am late to start but I guess its never late to learn
Ah, let me double-check this, but most likely I\’ve taken the log-returns when I used the exponential function. For simple returns, you don\’t need the exponential returns.
mean and average .. are not they same ? how can you divide them ?
They are the same. Can you share some context on this? Thanks.
Dear Karthik , When finding trades in 1 SD range , we are taking current market prices 8337 ins this example . But I am sure the average / mean of normal distribution is somewhere else . But as per my understanding 1 SD + – is to be seen in context of the mean value and not the current value of Nifty in this case ? Kindly help me to clearly understand the concept
Thats right, Rajendra. You need to look at it from the current market prices perspective, as in you will have to do the same with the latest prices.
Hi kartik can you tell in excel sheet bin array function, how you used it?
I\’ve explained that in one of these chapters, Shrikant. The key point to remember is to use ctrl+shit+enter when pressing enter.
The Bollinger bands give us the same SD variance plotted on the chart wrt to a 20 day moving average, right? The same can be used as an alternative to normal distribution range?
Yes, you can use the BBB as an alternative for short term SD.
Thanking you so much Sir.
Have a great evening 🙂
Welcome! Happy reading, Harsh!
Good evening Karthikji
Thanking you for rply to above query.
Well no I\’m not new to market I\’m since 2008 😅. Yes I\’m new in F&O space since 2017. Yes u r right that returns r crazy in bulls phase not only in pre-2008 but recently in 2017 where more than 700 stocks gave more than 100% returns!! But that\’s largely from midcap & smallcap space. Largecap especially bluechips except banking & IT others had struggled to give 15% returns also (but yes still better than risk free FD returns ) 🙂
Anyway so can we apply Volatility based Stoploss plus 1% extra buffering to negative returns stocks apart from other checklist like technical & oi analysis ??
Kindly rply to this above query. Thanking you 🙂
Yes, Harsh, you can 🙂
Good morning Karthikji
1)What to do if average 1 year return is negative ??
For eg- Nifty avg return is positive number say 10% which can be converted to daily, weekly or monthly return avg. But since many top Nifty stocks had given negative returns For eg- Indiabulls housing had given -58% negative returns then how we shall proceed with daily avg & thereby calculating Std Dev
2)Also Bear swipe is brute. It\’s easy for stocks to go more than 50% down in year but harder to give even 12% returns in bulls phase. So is there different calculations approach? Because such big negative returns give bizarre even 1 std dev results! What to do for this ?? 🙁
Thanking u for your time & have a blessed day 🙂
1) This can be a tricky situation. In case, of a compelling trade situation, I\’d look at other parameters to trade besides the returns.
2) I\’m guessing you are relatively new to markets (less than 4 years), is this true? Because in a true bull market (pre-2008), the returns can be crazy 🙂
Thank You 😃
Okay, I understood now! That you used it for plotting the Normal Distribution Graph of Nifty.
But can you please explain me the calculations of:
Bin Width (why divided by 50)
Bin Array ( why add by $H$10 function?) and,
Frequency?.. Didn\’t get the calculation of that at all
50 —> It depends on your data size. If the data points are many (more than 500, maybe 50 or 100 will do)
Bin array – to ensure all bins are of equal size
Frequency – This is an excel function.
Hello Mr. Rangappa
I\’m a bit confused with why you calculated the Bin Width, Bin Array & Frequency in the sample excel sheet of the calculations. Meaning, what is the use of it? I didn\’t get that…
This is to help you plot the distribution of the data points, especially to see if the data is normally distributed.
How do we arrive form to exponential(26.66%) value
Meaning? Can you kindly elaborate this?
hello karthik,
I did not understand the converting log % to normal% part could you please explain how to arrive to that number
Ashutosh, when you convert log to normal, you are essentially converting the number from a log scale to a regular number.
Hi guys
first of all thank you very much for all the explanations and all the learning you make available.
I just don\’t understand why the standard deviation here is multiplied by 2.I read few times the chapter and my understanding is that the 2SD is related to the distribution theory.If my understanding is right I don\’t actually get why applying *2 or *3 to the standard deviation.My understanding of the theory is that you have like a basket of observations represented by the 100% of the cases observed, in which the first distribution represented by the 68% of the cases falls let\’s say in the central bins, the second represents the 95% of the cases and the third the 99.7%.
Said that and assuming my understanding of the 1SD and 2SD mentioned in this chapter is right, I think the first SD should be calculated on the 68% of the observations (the daily returns between -0.85% and 0.89% in your file), the second 95% on the daily returns between -2.27% and 2.89% of your file and the third with the daily returns between -3.69% and 3.26%.
While I perfectly tie back with your calculation for the overall period (0.038325% average daily return and 1.045661% annualised standard deviation), I calculated an annualised daily return average of 0.035014% and annualised standard deviation of 0.450559% taking the first distribution (daily returns between -0.85% and 0.89%), respectively 0.06858% and 0.951959% with the second distribution (returns between -2.27% and 2.89%) and 0.03832482% and 1.044886% with the third distribution.
But I may have misunderstood what you mean with 1SD and 2SD.
Please let me know what are your thoughts about that
Thank you very much for your support
Pasq, I read your comment a couple of times, I\’m not sure if I completely get it. 2SD, is simply adding 2 to 1 SD, which as it implies leads to 2 standard deviations. Likewise with 3SD.
Sir, As per the Standard deviation formula i did calculated the 1st SD range for nifty. I did virtual trade option writing in these CE and PE options. It was is profits only. Thanks for a such wonderful strategy. Inspired. I want to move to real trade, my question is , on the day of expiry what would happen if I don\’t find any buyer to square off my position ( if my options are expires in OTM ). Do the exchange will impose a penalty to me?
Your option will be squared off and settled by the exchange.
Hi sir,
Please correct me for the calculation of mean of a stock.
Mean = sum of % daily returns of a stock for 1 year divided by total no. Of days??
Is it correct? And for calculation of SD it is in NSE page as volatility.. Likewise is there any source to get mean of a stock?
Bala, that is the right formula. No, I\’m not sure if any websites helps you calculate the mean of a stock.
in Excel sheet, I don\’t understand in bandwidth why it is divided by 50
sorry, please explain Bin width, bin array and frequency, what the useof it
I\’ve explained this in the chapter itself, Vinoth.
That is to create different buckets, Vinoth.
sir, I am learning algo trading and also quantitative strategies but I couldn\’t understand why people use log return instead of arithmetic returns like daily return.and in above in one calculation u were calculating 1-month return but u have used 30 instead of 22 to calculate the monthly return
Log return gives you a slightly better representation of true returns, this is true for shorter look-back periods. Guess I have explained this in detail with an example somewhere in the comments. Can you please look it up? Thanks.
Hello,
What is the logic behind using exponential function as opposed to normal one in the Range calculation?
THANKS
Guess the returns are calculated using log returns, to convert it back to normal scale we use the exponential function.
Hi Kartik
Where can we find the historical implied volatility data for nifty and any stocks.
Is india vix and implied volatility same.
Aasim, India ViX is implied volatility. There is nothing like historical implied volatility….I mean, the current implied vol becomes just the historical volatility t\’row.
Hi Karthik,
I got a doubt here.
We have types of volatility
1) Historical Volatility (which you have calculated earlier based on stock price)
2) Forecasted Volatility
3) Implied Volatility
Realized Volatility which is nothing but past implied volatility (actually volatility which occured earlier)
Now, when you are using \”Normal Distribution\” and calculating (+1 SD, +2 SD), the volatility here was calculated based on stock prices right.
Similarly, when you introduced \”Volatility Cone\” in the next chapter, you are calculating volatility based on \”Realized Volatility\” or simply past Implied volatility.
Up to this, let me know if I am correct?
If my above understanding is correct, suppose we calculated volatility (using stock prices) for the next trading day and think it came around (1.52) -> Volatility based on historical stock price data (Historical Volatility).
Now, in the next trading day, the implied volatility , the actual volatility which will occur can be different from what we just calculated(1.52) (Implied Volatility).
So, how come the past implied volatility could be same as Historical Volatility? Please let me know.
Thanks
Srikrishna
If i buy call option today and sell it a few days later before expiry, do i need to have margin to sell it?
Nope, you dont need margin to square off an option.
Hi Karthik,
I have few questions for you?
1. Is annualized volatility and historical volatility are same?
2. Just for info, comparing IV with HV determines the IV rank?
3. as per sensibull, is IV calculated based on Average of ATM(call & Put) of current month? or includes OTM strikes IV as well?
Thanks!
1) I can calculate the volatility as of today and then annualize it. Historical volatility is based on the past data
2) Yup, you can use this for a back of the envelope calculation
3) I\’m not too sure, maybe you should check with them.
You mentioned in module that option writes should be done before 15 days expiry date then what type of trade should be done just after the expiry? Will be appreciated for your response.
I mean, its best to consider writing post 15th of the month so that the time decay is in your favor. Earlier in the series, you can look at buying opportunities.
In the excel sheet i downloaded, Why BIN WIDTH = (H8-H9)/50. Why divided by 50 only? Can we do that with 100 or 60?
Okay. I got it. Read the comments above. No need to reply.
50 is an arbitrary number, it may as well be 25 🙂
Larger the data points, higher the number of bins.
Hi Karthik,
Can the Return Average be -ve? I think it can be however in that case when I do the range calculation of the current Nifty Trend then I get the below data. Do you think any problem with that? I took 600 days data.
Daily Average -0.03%
Daily Volatility 0.73%
Annualized Average -7.88%
Annualized Volatility 11.55%
Nifty Spot 10907
Range 3.67% Upper 11306.99
-19.43% Lower 8787.83
Looks alarming.. 😀
Suvajit
Suvajit, I think your numbers are very slightly off. Btw, yes, return range can be -ve.
Daily Avg = -0.03%
Yearly Avg = -0.03% * 252 = -7.56%
Daily Vol = 0.73%
Yearly Vol = 0.73% * Sqrt(252)
= 11.59%
So how did you get 3.67%
Hi Karthik,
I did Range Calculation
Upper Range=Yearly Avg +Yearly Vol = -7.56+11.59 = 4.03%
Lower Range=Yearly Avg -Yearly Vol = -7.56-11.59 = 19.15%
Is this correct calculation please?
Suvajit
Yup, it is.
How do we calculate IV rank. is there a way to do that using excel
Possible, but I think it could be cumbersome, Narendra.
Why is it that the lower end is much lesser than the higher end, in the volatility calculation? In 1 SD calculation of ranges of Nifty the upper range is around 27% but the lower range is only -7%. Aren\’t there chances there are equal chances of going up or down of the same value? Is there any specific reason that that i am missing out to see?
This depends on the past data as well. If the data has some sort of trend (strong), then there could be a bias.
This will work same for bank nifty weekly expiry?
Yup, it does.
= 8337 *exponential (26.66%)
= 8930
How did you calculate that value? i am getting a very large number while using = 8337 * exp(26.66) in excel.
I\’ll try and post a screenshot.
Ok thanks
how does – 68 %, 95 % and 99.7 % gets calculated of standard deviation in first example of Galton Board
These are the normal distribution properties, Vishal.
Hi Karthik,
You have given examples of how weights or heights of people follow normal distribution.
Is it that:
– Actual values of weights and heights follow normal distribution
or
– Deviation from mean of weights and heights follow normal distribution?
Thanks,
Akshay
I was referring to the actual weights. However, if you are talking about stock prices versus stock returns, then stock returns are normally distributed and prices are not. Stock prices can trend.
But the Bollinger Bands track movement of stock price away from its mean, not stock returns.
What am I missing?
Akshay, yes, BB is on the price and not returns. Frankly, I never thought about this – stock prices can trend, so BB bands may not be that effective.
Sir, in the excel sheet what is the term \”Bin width\” you have calculated and what does it mean?
That is the size of the bin which contains all the data points ranging from the lower bin value to the higher bin value. For example, if the data points are 2, 5, 7, 9, 3, 4.5 and if the bin width is from 2 – 6, then it will contain 2, 4, 3, and 4.5.
Hi,
Tks a lot. What i meant was that when we calculate Daily Mean from LN(D3/D2), i was getting negative figure, so got confused that should i take it as positive figure or it can be negative also.
Kindly guide where exactly can we get Daily SD of Nifty/Bank Nifty/Other Sector Nifty Indices?
Also, do we get IV of Nifty/Bank Nifty/Nifty Stocks readily for last 1 year to get range of IV for underlying. If so, where exactly to search for the same.
You can take the negative values of daily returns. There is no issue with that! NSE puts this information up on their site, click on any derivative contract and click on \’other information\’. IV is a little tricky I guess, Dharam.
Hi Karthik,
When we calculate \’Daily Mean\’ from \’Daily Return\’, can Daily Mean figure be negative? if yes, then should we take this negative figure into account to calculate 1SD n 2SD? Pls explain.
Tks a lot
I\’m not sure if I understand your query completely. Daily mean and daily return is the same. Yes, if this is a -ve return, then you will have to take that for std dev calculation.
Hi Karthik,
Where can i get Nifty Daily Volatity readily available?( e.g. For Wipro, i can go to \’Derivatives Quote page\’, n get it in \’Other Information\’)
Also, is it possible to get High and Low of IV of all Stocks(including Nifty) for last 1 year? If yes, then where exactly do we get it?
Tks a lot
You can do that for Nifty Futures as well. The high/low vol should be available with Sensibull, let me check.
Hi Karthik,
Your write up is super super lucid and easy to follow. I can understand the the kind of patience it requires to do write ups like these, clarifying each and every point.
Indeed, no one goes hungry (without any doubt in mind) after reaching such blogs.
Thank you very much.
Hey Altamash, thank you so much for the kind words, glad you really liked the content 😉
Hello Karthik,
When the average is positive – difference of upper limit with spot and difference of lower limit with spot is highly different. Is this calculation biased towards writing call options? Upper limit is too far from the spot and lower limit is too close to the spot, using this data how to write a strangle in NIFTY and BANKNIFTY?
Abbas
Not really, Abbas. This depends on the data points (also check of the stock/index has trended). I\’d suggest you replicate this calculation of few other stocks to check the way the numbers pan out.
Hello, Karthik can you please tell me how did you plot the normal distribution graph, I was using the NORMDIST function but I don\’t know what should be the input for \”X\” the other two is specified that is mean and SD but what about cumulative distribution function should it be true or false, can you please explain how to plot the graph or how to get the values of normal distribution after calculating daily returns, Avg daily returns, SD daily, annual SD. Please tell what are those values in y-axis thank you.
Dwijesh, I\’ve not used the NORMDIST function, instead, I\’ve used bin arrays and distributed the returns across the bins and then plotted a line chart over it. If the data (stock price returns in this case) is normally distributed, you will get a bell curve, which is what I\’ve got in these charts.
i got the daily mean/average as negative, because of this the upper limit becomes less and the lower limit becomes more negative. This happening is normal?
Yup, especially when the stock or index is trending down.
Amazing !!!
Thank a lot Karthik sir !
Happy learning, Arun 🙂
Upper Range = 16 day Average + 16 day SD
= 0.65% + 3.567%
= 4.215%, to get the upper range number –
= 8462 * (1+4.215%)
= 8818
Sir pls explain above calculation ? and how to take it in excel?
example from previous chapter was simple to calculate in excel as below
Upper Range
= 8337 *exponential (26.66%)
= 10841
Hello Sir,
Thanks a lot for the wonderful articles. I have a couple of questions.
1. I am thinking of buying NIFTY AUG 11800 CE. So I downloaded the historical data of Nifty from NSE for the period, 21st Aug 2017 to 20 Aug 2018 and calculated the daily return mean (0.07%) & SD (0.65%) using the excel as you have shown in the previous chapter. For Aug 30th expiry, number of trading days is 7. Hence, 7 days\’ daily return mean is 0.49% & SD is 1.72%. Current Nifty spot is at 11551.75. Hence I got the lower end of Nifty as 11410.53 & upper end as 11809.89. Since there is a 68% probability of Nifty hitting 11800, I can go ahead and buy right? Is my understanding correct?
2. Similarly, if I have to calculate the range in which any index or stock would trade for the next few days/weeks, I need to know the daily return average right? which means should I calculate it like I explained above every single time using the past 1 year daily return values?
1) The calculation is right, but I\’d suggest you do this writing options as opposed to buying options
2) Yes.
Okay. Thank you very much.
Welcome!
Hello sir
i really liked the way you explained the topics, i have a small doubt i, e in nifty example in excel sheet while calculating 1SD yearly you used =k9*SQRT(252) As formula but i don’t understand why it’s 252 and not 365 days.
Please help me understand the same.
I have attached a link for a excel drive please can you help me verifying it whether all the calculations are correct.
https://docs.google.com/spreadsheets/d/1ADgTIDH1fqQvYYbgaJPPWRNT4riXhllEn38wFIeWol4/edit?usp=sharing
Regards
Thank you
Guess, I answered this earlier.
Yes sir but I am not sure whether the calculation i have done is correct so if possible can you go through the excel file and let me know, it would be a great help to me to. validate my calculation.
Regards
Thank you
Running a very tight schedule today, but I\’ll try and do that sometime soon, Rishi. Thanks.
Thank you sir for your valuable time and clarifying my doubt , waiting for your validation for the excel file.
Regards
Rishi jain
how to calculate daily average?
Wasim, the daily average of what?
While calculating annualized numbers you took 252 but while calculating monthly SD you took 30..aint that suppose to be 22 then?
Yes, it does. I\’ll change it as soon as I can.
Hey Karthik,
I have seen in some cases the IVs of the stocks does not fall even after the announcement of the results. Could you tell me why this happens?
Thank you.
Yes, this could happen if the stock is influenced by its own event and the market event, wherein the market event follows through the stock\’s independent event. Example – Infosys\’s quarterly results on 25th and election results on 28th. In this case, the volatility will remain at elevated levels.
Thanks Karthik,
Have another question. Let me take example of ICICI bank. Quaterly Results for that script is tomorrow i.e on 27th. IVP of this month contract which is expiring today is 99 and the ivP of Aug contract is 85. These results wont effect july contract right? In that case ivp of Aug contract should be high right? Will the announcement of results effect the IV of Aug contract ? Same case for Axis bank. Results are on 30th and this month contract iv is high. Why the difference ?
Got these values from sensibull.
It will affect both the options. The sensitivity of the July contract will be higher than the sensitivity of the August contract.
Can we calculate intra-day volatility also ?
Please reply.
You can, Suhas but this requires you to build a volatility model using techniques like ARCH/GArch etc.
Thank you very much Karthik. However, request you to please explain ARCH/GArch
Please. Thanks.
Suhas, I\’m aware of these concepts but not to the extent where I can explain to others.
Maybe I should learn these concepts well enough to do so 🙂
It\’s okay Karthik. Thanks.
Cheers!
I had calculated the range calculation with 1sd for 2 days . It was 10963 as per calculations . and today nifty is in range of 10932
This really works if your directional bet is right. Made a small profit today as i wanted to check if my analysis was right. But i got out early as usual . Guess this has to be learned the hard way.
Hats off to you sir and to Zerodha for sharing this knowledge .
Yes, this takes time to get used to. Good luck, Shyam!
Hi Karthick,
By going with the above calculation, let\’s say if I taking some strike price which beyond the 95% confidence Level with 2SD. Those strike prices are not allowed to trade due to the limitation(range outside the trading level) provided by NSE right. Then, in that case, we can never use this to sell options which will go worthless right…
Request you to clarify if my understanding is correct…
Selvam, this may be applicable only with Bank Nifty weekly expiry. Other contracts should not be an issue.
Thank You.. got the point.
Hi,
Here are the calculations for nifty
1SD Daily Yearly 30 days
Average 0.04% 10.42% 1.24%
SD 0.65% 10.37% 3.58%
CMP 10699
Range Calculation with 1 SD
1 year
Upper 20.78% 13170
Lower 0.05% 10704
30 days
Upper 4.82% 11226
Lower -2.34% 10451
I understood the calculations part. My following queries are :-
1. What SD should we use say if I need to trade banknifty options? Which one do you use?
2 .In 30 days lower range i am getting – ve value whereas in 1 yr lower range i see it is +ve. how come?
30 days
Upper 4.82% 11226
Lower -2.34% 10451
1) Calculate the daily and convert it to your desired time period. This is what I use.
2) I think your calculation for 30 day is wrong. Can you please check that again?
Hi
Please see below link. calculations done.
https://drive.google.com/open?id=1jbg1WxJBDueh1i44KaKK6RmcjfY8oXUL
Can you please check the calculation for 30 days lower range. Unable to find out the error
Will try and do that over the weekend, Shyam. Thanks.
Hello Karthik ! Is the composition of nifty (i.e the fifty stocks it contains,weightage adjusted ) also normally distributed? What i mean to say is if say nifty rises 1% for the day,then 68%of comprising stocks should be in 1%+1S.D range or 1%-1S.D range and so on.Does this holds true or not?N how about going for a pair trade by going long and short simultaneously in the either end of the spectrum then?
Not really, Anshul. Only the daily returns of Nifty are normally distributed, not prices or the index constituents. You can try doing calendar spread on Nifty by going long and short on Current and mid-month contract.
Hi,
I\’ve calculated SD and average of nifty data from (6 jun 17, – 5 jun 2018) with log returns. Daily and yearly average come 0.04% and 9.61%, Volatility come 0.64% (daily) and 10.20% (yearly) and CMP 10594 . Using this data 1 year range come Upper Range 19.81% and Lower Range -0.59% with this exact range comes 10532-12914. Upper Range seems good but i think there is something wrong with lower range So can you please tell me where is the mistake.
Please answer asap as long way to go.
Gurjeet, this is quite expected as the daily avg is positively skewed. I\’d suggest you look at 1.5 or 2SD.
First of all thanks for reply. I calculated the 30 day range with 1 SD it comes 10345.47-11099.6 and 1 year range with 2 SD
9511.21-14300.86. From this i think there is something wrong on yearly average so is there any solution to fix this ?. So i was right but there was some average issue right ?.
Gurjeet, the average has a positive bias so it is not surprising that you\’ve got such values.
Hi Karthik – Sorry to bug you again but, when doubt comes you are the only recourse.
So, when you say positive bias do you mean Average is positive? If, yes then does it mean if average comes out to be negative then positive upside will be less than downside?
Also, saw you mentioning in one of the comment that you will let us know the calculation of range when Average is negative have you already done that if, yes appreciate your providing the link for the explanation.
Vivek, ideally the daily average return should be as close to as zero. If it is near zero, then the range calculation will turn out much better. If the average is slightly positive, like say 0.4%, then the range tends to be slightly positive. Likewise with a slightly -ve value.
I have explained this somewhere, I\’m unable to trace it back myself 🙂
Hi Karthik,
When we are calculating the annual returns or SD or anything, how many days should we take? is it 365 or 252? in some calculations you have taken 365 and in others 252? from where does this 252 days come? plz explain.
Also for daily average returns should the no.of days be same as we take for annual calculation? will the average returns and SD keep changing as no. of days change?
Thankyou
Priya, I prefer to take 252 days as this represents 1 full trading year\’s data. Apologies if I have not been consistent in calculations, but yes, 252 serves the purpose.
Hi Karthik,
For calculating upper and lower range I used excel\’s exponential formula. I calculated upper range and lower range which you have mentioned in the explanation above has different figures as follows:
As per excel
Upper Range
= 8337 *exponential (26.66%)
= 10884 (as per explanation above=10841)
And for the lower range –
= 8337 * exponential (-6.95%)
= 7777(as per explanation above=7777) this is correct.
I need to look into this, Kunal. Will get back as soon as possible.
Hi!
Thanks for the wonderful explanation!
However, I\’m facing a dilemma here regarding a real life example of volatility. As of today (13th May 2018), the daily volatility of PCJewellers as per the NSE website is 14.59%, while the annualized volatility is 278.82%!
So, if volatility of any stock is greater than 100%, would it mean that the range for the stock extends from being worthless to being double or triple it\’s current value for that given period or is there something that I am missing out?
Yes, that\’s exactly what it means, however, the downside is capped to 0 as stock prices cannot be lower than that.
Thank you for the reply. You are doing an amazing job educating people about this and enabling them to explore markets with a sense of market literacy. Can\’t thank you enough. 🙂
Keep learning, Anshul 🙂
Hello sir,
As you said in previous chapter that
Mean annualised = mean daily * sqrt (days)
But in the above explanation you said that mean annualised = mean daily * days
Can u plz clear this doubt.
Thanks in advance
Ah, I think that\’s a mistake. You can multiply the mean by the number of days but SD you will have to multiply with the Square root of time.
Hai!
I have a doubt. How do we know whether volatility is high or low? Say the IV of stock is 34%, then is it high or low?
You can always calculate the historical volatility and compare this with present-day vol to get a perspective.
hi Karthik,
Using your excel sheet suppose if I\’m calculating SD for a company which has issued bonus in the last year (example – M&M), does the excel produce correct results or any correction is required to account for the decrease in the share price after bonus is issued?
No, not really. The excel is static and does not adjust to corporate actions.
I have created a Galton Board that demonstrates this idea. It is call The Random Walker. See http://www.therandomwalker.com
Enjoy.
Thanks for the link, Mark.
Hi Karthik
Even if there are 100s of comments still i wanted to salute you for bringing this kind of tough topic in a easy manner !, couple of questions with curiosity .
1, Have you ever traded options based on 1SD or 2SD ? and what is your winning rates ?
2, I can see on tastytrade.com they talk a lot about both SDs and the trade opportunities related to this , specially strangle strategies , do you have any words on this ?
3, Have found a website stockmaths.com where i can get SDs as of now and historical too , compared your XL template calculation with it and its matching , have you ever tried it ?, would it be a reliable source of SD?
4, On your XL sheet you had used about 4 years data, is it ok to calculate SD with just 1 year data ?
Regards
Neeraj.
1) Yes, multiple times. At 2SD, I\’ve had greater success but the profitability is low. Maybe 3 (or maybe 4) out 5 were successful.
2) I\’ve not used tastytrades, so no idea.
3) Thanks for sharing the link, I\’ve not used it. Will try and look it up
4) Yes, in fact, the better approach is to look at 2 years, 1 year and last 6 months SD. Gives you a perspective of how the SD is changing.
Good luck!
where do i find implied volatility chart of underlyings for indian market?
I\’m afraid these are not available.
how calculated Upper & Lower range,
Upper Range
= 8337 *exponential (26.66%)
= 10841
And for lower range –
= 8337 * exponential (-6.95%)
= 7777
because as my opinion
Upper Range is:
=8337*1.2666
=10559
No, we use exponential to convert the log scale back to normal scale. So go with exponential.
Very interesting topic. You are a genius, Karthik!
Thanks for sharing such insight.
\’Genius\’, is a big word.
Thanks for the kind words, anyway 🙂 Happy learning!
Hello Karthik Sir,
If we need to calculate Banknifty deviations for 1-week expiry then a percentage based volatility is better then exponential based volatility calculation as you said that exponential is better for more than one-year calculations or it also gives an edge for shorter periods as well, as in the case above.
And in excel sheet you\’ve provided above I see you\’ve used 252 ( trading days ) in a year for calculations, but when it comes to a month you\’ve used whole 30 days, is that 30 days are 30 trading sessions??
Vinay, yes look at the regular % returns for less than 1-year time frame.
That is a good observation – maybe I should use 22 trading session for monthly calculation.
Hi Karthik,
I saw that you are using exponential calculations to calculate volatility.
Instead of using the exponential calculations. Is it possible to calculate is using the below formula\’s.
Daily Return = (Today\’s Close – Yesterday\’s Close)/ Yesterday\’s Close
Daily Volatility = STDEV ( Daily Return )
First Standard Deviation(Upper Range) = Spot Price*(1+ (Daily Return * Days) + (Daily Volatility * SQRT(Days)))
First Standard Deviation(Lower Range) = Spot Price*(1+ (Daily Return * Days) – (Daily Volatility * SQRT(Days)))
Does this formula looks correct to you? It\’s the same as yours only I removed the logarithmic base.
Regards
Kulbir
There is no difference (or very small difference) between percentage based volatility and exponential based volatility calculation when time period is small (t->0).
However if one is calculating volatility for long periods, its best to use exponential calculation.
For ex: If you calculate volatility for long periods of time using % based method, you might endup with a negative stock price (not a possibility), however, you would never get that with the exponential calculation
Hi Karthik,
Thank you for your reply.
As you said that Volatility Calculation for longer periods based on percentage formula can give incorrect results. What do you mean by longer periods ?
For example in my case I am using stock prices of 1 year to calculate volatility and daily return.
Regards
Kulbir
By longer, I have one plus year in mind.
ok, thank you Karthik for the clarification.
Welcome!
Hello sir,
It\’s been amazing reading it, little doubts by average you mean = MEAN of last one year daily returns AND will the 1st SD levels would be good for bank nifty as it expires within a week and it\’s volatile also
Yes, mean=MEAN 🙂
You really need to check this, Bank Nifty is volatile, wont be surprised it it swings 2 SD in a week 🙂
As the range increases the confidence level is also increasing, I\’m a bit confused about it. That should be other way round??
No, as the range increases, there is more room to accommodate the volatility, hence less room for error, hence more confidence.
I have done all the calculations for NIFTY expiring 22nd feb and upper limit tends to be 10720 and suppose if we sell Call option 10750. How to calculate the stop loss referring to the above example? The OTM transits to ATM (10750)? Thank you.
In this case, you really need to have a tight SL as you\’ve already have buffered enough safety. For example, if I have written the option for 10, I\’d start feeling uncomfortable the monment it goes above 12 or 13.
I have downloaded 1 year data of aurobindo pharma stock close price form nse since it allows for 365 days but nothing changed in excel sheet after filling in price column. can you please help me sir….
Also whether i have to change anything in frequency ?
Hi Karthik. This is Omprakash. Article was really wonderful. I have downloaded the Nifty Example Sheet. I am little bit confused. Just tell me whether put the close price of any stock for 1 year I can get the data correctly means the range it will trade for the month If I am wrong please correct me.
You can try doing that, OM. Please check if the cells are properly linked to the formula.
In the excel sheet downloaded, for \”bin width\”, you have calculated =(h8-h9)/50. How did you arrive at number 50? Also find a way to update website, so that we get email alerts, whenever you respond. It haappens in other websites.
50 is arbitrary and I assumed it based on the number of data points. It can be 25, 50, 100, or 200 based on the number of data points.
Hi Karthik,
Instead of using Log Average Calculation, can we use the normal Calculation for Daily Returns like this,
\”\” (current close / previous close) – 1 \”\”. It gives same Results, still I need to cross check again …
Yes, you can use that calculation.
Can you please elaborate on how did you arrive at 1.046 ? Daily Standard Deviation / Volatility = 1.046%. I am stuck here and it will be very helpful. _/_
Let me check this Rohit.
Awaiting for your reply.
I\’d suggest you run the excel function \’=stdev()\’, on the daily returns of Nifty. Do this on the same set of data that we have used in this chapter.
how to calculate exponential plz help
Note these % are log percentages (as we have calculated this on log daily returns), so we need to convert these back to regular %, we can do that directly and get the range value (w.r.t to Nifty’s CMP of 8337) –
Upper Range
= 8337 *exponential (26.66%)
= 10841
And for lower range –
= 8337 * exponential (-6.95%)
= 7777
how to calculate exponential what is formula plz help
You can you the \’=exp()\’ function in excel for this.
If we want to calculate the Daily volatility. How many days shall we consider for calculating daily returns. I mean last one year, two years , four years(As per your excel) or more. And can we interpret that more number of days means more accurate results we will get
At least 1 or 1.5 years will help.
Hi Sir,
Can we do the 1SD and 2SD and 3SD calculation as simple like this …
we can get the Daily Volatility Data from NSE website on daily basis, \”… In the NSE home page, click on ‘All Reports’ and select ‘Daily Volatility (CSV) … \” …
On Nov 21st, Jetairways Daily Volatality ( means 1 SD ) is 0.0368
If we want to know the next 15 days Volatility can we calculate like this ,
1SD : 0.0368 -> 0.0368 * 100 = 3.68%
1SD * Sqrt(15) = 14.25%
CMP : 663.50 ( close price )
14.25% ( 663.50) = 94.54
So the Upper range ( 663.50 + 94.54 : ) is 758.04 and Lower range ( 663.50 – 94.54 ) is 568.96 …
2SD Calculation ( 1SD * 2 ) is 94.54 * 2 = 189.08 …
Can we proceed like this …
Yes, this works!
Thank you Sir …
Cheers!
What about adding SD to Avg and then finding a range
You can use Bollinger bands for that!
1)When i calculate Daily volatility it comes 2.04 for tata motors for last 365 days.Am I right???Is my calculation correct ???On NSE website it show daily volatility has 1.65.
2)When i calculate average for tata motors for last 365 days its comes -.091% it it right value , could please advice.
Venu, try the same calculation for 252 trading days. Also, I guess NSE\’s volatility calculation method is slightly different. Average could be correct. Hope you\’ve used the excel function \’=avergea()\’, on the returns.
Hello,
I have one doubt here.
In above excel you calculate probable volatility. For that you have consider nifty from 2011 to 2015.
Now, suppose I have calculate volatility for net 10 or 15 days only so, for that how much past record should we consider.
Means, to calculate volatility for next 10 to 15 days should we consider the same past record for 10 to 15 days back.
or, is it a random selection…?
Not random, really 🙂
If you want to do this for 10-15 days, then you need to look at at least 6 months of past data.
How did you calculate MEAN 0.04%?
Average of returns, use excel function \’=averege()\’.
Thanks @Karthik. Standard deviation for sample data you have taken is 1.046%. Can you specify the date range for which you have calculated? When I try to calculate it from (2014,7,22) to (2015,7,22), it is 0.896.
I\’d request you to please check the excel 🙂
Why I can\’t extend Freq column range in your formula.Please help me.I want to add more column data.As per your data range = FREQUENCY(E9:E1096, G14:G64). I can\’t extend more than E1096 data range.What i want to do? Thanks for advance. I m trying to attach snap shot. But don\’t have option.
You just have to extend your selections to accommodate more cells.
Thanks for your reply.But actually array formula can\’t edit as usual.I find from the forum for edit. \”After you edit, press CTRL+SHIFT+ENTER not just ENTER.\”That\’s all. I really need to lot of thanks such a wonderful describe about options. I like it so much the way you example and describe.You have a great talent.Hats off to you.
Yes, all array function requires you to key in Crtl+shift+enter.
Good luck and happy learning, Anantharajan 🙂
In the example of volatility used to calculate the stoploss( airtel), The upper and lower range for 5 days is computed by using volatility only. Shouldn\’t we take the avg. daily return of airtel, in this case, to calculate the range for 5 days as done is previous examples?
Also, I would like to thank you for the articles you have shared here. Great work.. Kudos.
We should be using the average daily return. Let me recheck this. Good luck and happy learning.
When I calculated the average daily returns for nifty for the last one year ( 15 jul 16 to 14 jul 17) the value turned out to be negative. And when I annualized the returns ( both volatility and average daily return) and added them it\’s still a negative percentage for the upper limit at 1sd. How come this be true? Does that mean nifty is bearish?
Also in your calculation, you have taken the average of daily return for nifty over 4 years. What is the rationale behind that? How many years of data should one take to find the average daily returns and volatility if you are looking for a time span of 15-30 days vis-a-vis 3-6 months?
The daily volatility shown in nse website, is it calculated in ln scale?
Avg daily returns can be negative, however, this may not be the case with Nifty as the markets have been trending upwards. Ideally, for a 15-30 day period you should look at maybe 1-1.5 yrs of data…and for 3-6 months…at least 2 years.
I\’m not really sure about NSE\’s calculation.
I tried deriving the daily average from daily volatility for nifty from the nseindia site
daily volatility is the exp( daily average)
(a)Current Nifty : 9615
(b) daily volatility(sd) : 0.49 – nseindia
(c) days to expiry : 17
(d) daily average : ln(b) = (-0.71)
(e) volatility for 17 days : (b) * sqrt(c) = 0.49 * sqrt(17) =2.02
(f) average for 17 days = 17 *(d) -0.71 =-12.12
when i add e and f for the upper range for 1 sd i get a negative number and hence resistance is coming lower than the current price.
For other stocks this method is working fine.
Daily average can be calculated by running a simple average function on stock return. Step (d) seems redundant.
I am trying to avoid the downloading of historical data .. as daily volayility is readily available.
When i tried the above for nifty, the 1sd upper range came in negative for nifty.
This worked for me till now but when the upper range is negative the resistance goes below the market price and hence wondering what am doing wrong.
I can send you the excel template on the mail which might help in understanding what and where am going wrong
Not sure if I can run through the excel, Varun. I think you are taking the wrong approach while calculating daily average.
I calculated historical volatility using stdev.p function with simple return (B3/B2-1) data of index during one year. In order to have max & min value we need to have mean of the return.
How can we calculate mean value? Just using \”mean\” fn of excel, i think , is not sufficient. The mean should be calculated using normal distribution.
You can use the \’=Average()\’ fn in excel.
hi ,
How can i find probability of particular (given) value in next two month when the current value is given . pl guide me
If the given value stems out of series which is normally distributed, then you can extent this and assign a probability to it.
First I wanted to thank you for detailed and elaborate info.
i wanted to ask you one question
in the excel file why have you taken bin width as =(H8-H9)/50.. why 50?
thank you
50 is the number of bins. You can select this based on the number of data points you have. Higher the number of data points, larger is you bin size. No preset formula to decide this.
Hey Karthik,
To calculate the SD, why do we consider the daily returns. Why can we not do it using the closing prices?
i.e. take the closing prices, calculate the mean, variance and then SD?
Thanks.
For all such calculation we consider the daily returns, and not closing prices. One of the main underlying principles is that the returns are normally distributed while the closing prices (or stock price in general) are not.
First I wanted to thank you for detailed and elaborate info.
I have few questions to ask
How do you convert log percentage to normal percentage? or am I missing something. what does exponential of a percentage signify. Please if you could explain this. just once
To convert a log number back to a normal percentage, we take the exponential.
Dear Sir, Thank you for such wonderfull writing, I have become a real fan of your articles. I was doing the calculations here for Federal bank and I dont get a normal distrubution, can you please help to check this and let me know if this is not in normal distrubution. I took the data for Federal bank for last year i.e 1.1.16 till 31.12.16. I really appreciate if you can help me understand if Federal bank is in normal distrubution or not.
Thanks for the kind words, Murali. Most stock returns are normally distributed. I will check this as soon as I can.
how to calculate Daily Average / Mean = 0.04% of nifty.
Use the standard excel function \’=AVERAGE()\’ on the daily return time series.
Really Appreciate all your efforts to write such a nice article/book. The articulation, language and the ease in explanation is really amazing. You are an Star Karthik!! Keep it up.
Thanks for the kind words, happy learning 🙂
Sir how did you get these numbers 68%,95%,99.70% is these are natural
Check out section 17.2 – the Galton board experiment.
Sir, you pls calculate exponential of the log to get the simple return. it is very confusing
Thats the math part 🙂
Hi zerodha
when calculating L&T daily avg i am getting negative value, (i.e daily avg = -0.14%, so annual = -36.13%), But Std Dev annual = 28.07 is positive. because of which i cant able to get upper and lower range. eg ( upper range = avg+sd= -36.13+28.07=-7.06% and lower range = -36.13-28.07=-65.01) so upper range of LT 1467 and lower range 826. But current price is 1583..
So it is a 3 sigma event 🙂
hi karthik,
If you can explain how to calculate upper and lower value when daily average is Negative, with support of example it will really helpful.
Will try and do that sometime soon, Nakash.
Have been going through your articles and to say they are lucid and informative is an understatement.
On September 18 in one of replies to queries on the volatality chapter , you had mentioned you would be writing a chapter on calculation of range when mean is negative.
Have you done that and could you okease provide the reference if that chapter.
Vimal, thanks for the kind words. Unfortunately, I\’ve not been able to do that. I\’ll try and do that as and when possible. Thanks.
In the previous chapter, you had used 365 as the base. However, you have used 252 as the base here. Why so ?
Ideally it should be 252.
Sir i have one doubt ! Why do we use log normal while calculating returns.. rather than simply multiplying with the no. Of days
Using log normalizes the numbers and brings it to the same plane.
Thank u sir!
Welcome!
Hi
Would you please let me know, in distribution of Nifty’s daily returns graph (image with blue vertical lines), x-axis is % of Returns, what is the y-axis.
Thanks
Y-axis represents the number of times a certain return has been generated in the past. For example in Nifty, approximately 80 times a return of 0.2% has been generated.
Hi
Thanks for clarifying, now it makes sense.
Regards
Cheers!
Solution 1 – (Nifty’s range for next 1 year)
Average = 0.04%
SD = 1.046%
Let us convert this to annualized numbers –
Average = 0.04*252 = 9.66%
SD = 1.046% * Sqrt (252) = 16.61%
I have a confusion with the multiplication of figure 252 (i believe we should use 365 here instead of 252 ) in the above equation and siting example from the 30 day Mean and Std. dev numbers from 4-5 lines below., i also believe that in the above quoted equation ( the one i am citing in this example ) The average should (Annualized ) should be written as = 0.04%*365 & not Average = 0.04*252 = 9.66%
Please clarify my both doubts
Yes, you can use 365 days, no problem with it. In fact, I think NSE uses the same.
Hi Karthik, I could answer my above questions by visiting the last two chapters and the excel sheet which you shared. sorry for posting the basic questions above. Thanks for your detailed explanation.
Glad you did 🙂
Hi Karthik,
I am trying to link between previous chapter and the beginning of this chapter. Not sure whether I am missing any thing here.
In the previous chapter(16) I learned about the Daily Returns, Daily Volatility and Annual volatility.
However in the beginning of this chapter(17) you have mentioned that,
\”In the earlier chapter we had this discussion about the range within which Nifty is likely to trade given that we know its annualized volatility. We arrived at an upper and lower end range for Nifty and even concluded that Nifty is likely to trade within the calculated range.\”
I am confused that where did we discuss about the upper and lower range of Nifty. I see only for Wipro.
Also the below points from this chapter.
\”
Daily Average / Mean = 0.04% —- How do calculate this?
Daily Standard Deviation / Volatility = 1.046% —— Is this daily volatility?
Current market price of Nifty = 8337\”
I am sorry to bother you. I have been reading this Options module for last one week. I stuck here as I could not find the link between end of the chapter 16 and the beginning of the chapter 17.
I guess the range calculation is mentioned in chapter 15, towards the end. We discuss the range for both TCS and Nifty.
Daily average is simple – select the daily returns and use the function \’=Average()\’ in excel. The same is explained in the excel.
Yes, that is daily volatility.
Good luck.
Dear Karthik,
Thank you for the wonderful article.
I wonder is there any web site who can provide the high/low volatile stocks compared to their 30-day,180-Day, 1 year averages?
What is the best time period to compare to understand if the stock is high/low volatile compared to historocal volatility – i.e 30-day,180-day,1 yr?
I am assuming by knowing high/low volatile stocks compared to their historical volatility one can understand the options on that underlying stock are having high/Low IV index – is this assumption correct?
Could you please help me in understanding the above
Regards
Sekhar
Unfortunately, I\’m not aware of any site which would give this information (accurately). One can certainly develop a deeper insight into trading options by looking into Volatility.
Karthik, Thank you for the reply.
I have a question on NSE web site\’s Daily and Annualized Volatilizes and options IV an don Vega values
1.Does it make any sense to compare annualized volatility with options IV [ from options chain ] ?
or Do we need to theoretically compute option prize every time to understand if the option premium is over priced or under priced?
2.Is there a way to quickly understand if the option premium is over/under priced and the IV is high/low?
3. can we derive some useful information on IV from options Vega values [ assuming if we have Vega live data ], meaning if Vega is above value X the IV is high and vice versa
Appreciate your help,
Regards
Sekhar
Regards
Sekhar
1) No, but lots of traders use this from a \’quick and dirty\’ perspective to get a sense of how cheap or expensive the option really is
2) Yes, most easiest method is by comparing IVs with historical volatility, also I\’d suggest you read the note on \’Volatility Cone\’.
3) Yes, again I\’d suggest you read the note on Volatility cone.
Thanks.
Karthik, Thank you for your prompt reply.
Sure, I will revisit the Volatility Cone section
Regards
Sekhar
Cheers.
Dear Karthik, thank you for the wonderful article.
I have a question on calculating yearly and 30 days SD from the NiftyExample.Xls. while calculating yearly SD we use Sqrt.252 which is the # of trading days and Sqrt.30 while calculating monthly SD which the total number of days.
From NSE website the way they have calculated \’Annual volatility\’ is daily volatility*sqrt 365 [ for example for nifty ]
Can you please help me in understanding what is the best way to derive Annual volatily and X-period volatility from daily volatility
Thanks and Regards
Sekhar
I\’d suggest you stick to the time count convention used by NSE i.e 365 as you would be more aligned to market prices.
Karthik, Thank you for your prompt reply. Similarly, Can I go with actual number of days[ ex: 7 for a week, 30 for a month] in calculating SD for any period?
Regards
Sekhar
You can adopt any time count convention as long it is aligns with market rates.
Karthik, Yeah, got it, thanks a lot Karthik
Regards
Sekhar
Welcome!
Dear Karthik
Wonderful explanation and a common man also can understand the way you have explained it. One question is still unanswered which is on look back period. There must some rule for look back period for a given future time horizon. Say I wish to get 99.7% confidence for next one week range prediction, what should be look back period for SD, Similarly what should be look back period for SD for next one month range prediction. If I choose any number of look back period, the SD and average return will vary and output range will also vary, may not be to a great extent but still theoretically we should plug the question to be more precise.
The higher the Standard Deviation, the higher is the accuracy. However, with higher accuracy the range also increases. For example 3SD is more accurate than 2SD, which is more accurate than 1SD. Accuracy in this context is simply because of the virtue of it including all possible data points.
Thanks for your reply…… my question was on look back period, should we always take last one year data or we should change the range? Apart from this, you have suggested to add last one years average gain to find out future range = spot price ×(average return+volatility %)for upper limit. Will it not be wrong when market goes in apposite direction. May be the past return was calculated in uptrend and now there is downtrend.
The look back period depends on the extent to which you intent to predict the raneg. If you are trying to forecast the range for the next one year then clearly look back period of 1 year is required.
Also, we consider both the upper end and lower end of the range…so this kind of takes care of down side.
kindly show the calculation ,if i know max,min and average volatility then how to calculate standard deviation.if i know only three thing max,min,average volatility value.
The SD calculation on excel is explained in the chapter. Request you to kindly go through the same.
Thank you sir. My question: If I sell 420 CE at 1.00 for a lot size of 1500 (at this time the spot price is 360). So I get the premium of 1500. On the expiry day the Spot price is below 420. So I do NOT square off and allow the trade to expire on its own so that I keep the premium received. Now how will the tax and other charges be calculated in this case. can you please explain with this example. Thanks.
No tax implication here as you are a seller of the option. However, if you had bought options and let them expire in the money then you will have to pay a hefty STT, check this post – http://zerodha.com/z-connect/queries/stock-and-fo-queries/stt-options-nse-bse-mcx-sx
Thanks Karthik for simplifying things for us!! I have few doubts related to volatility chapters. Could you pls share few mins to resolve.
1- In chapter-15, we simply calculated the yearly range of Nifty, with spot price and annual volatility. But, included daily avg/mean in the following chapter-17 for the same. Pls elaborate.
2- Why do we use log return instead of simple return? And why did we again converted log percentage into regular% to get the range value.
Thanks in advance
Aditya
If you need a yearly range, you need to take the yearly number. If I have used daily numbers, I may have done a mistake. I need to re check this.
For log returns, please check this – http://tradingqna.com/3574/why-stock-returns-are-calculated-in-log-scale?show=3574#q3574
Dear Sir,
I am lil bit confused,Can you tell me
what does dialy volatility in NSE website denotes?
Does it denotes Daily Average or standard Deviation?
is there any relation ship between Average and Standard Deviation?
Daily Volatility represents the daily standard deviation. Daily standard deviation gives you a sense of how much the stock/index can vary on any given day, which in other words is the volatility of the stock/instrument. Higher the daily standard deviation, higher is the volatility of the stock/index.
Dear sir,
It may sound stupid but I am not able to resist myself asking this. Why are we calculating daily returns, instead we can find out the SD, mean directly on the daily closing prices itself. This would give us the range of closing prices for 1SD/2SD/3SD directly. I tried doing so but somewhere i am missing something. Not able to find out the mistake. Please clarify.
You can calculate SD and other things on the prices – this gives you how your capital will fluctuate but what really matters is how your returns fluctuate, after all your P&L is a function of the variation in returns. Hence the preference for calculating these on returns and not really prices.
Honestly, i owe you a drink. This is the way to explain boring concepts. Keep it up. Cheers
I prefer whiskey on the rocks please!
Cheers!
WHY BIN WIDTH IS 50 IN DENOMINATOR IN EXCEL SHEET
This is completely arbitrary. It depends on the number of bins you need…for example – if the data set is large, say 500 odd, I\’d choose 50 bins.
sir, how can we get Daily Average / Mean =???????
Calculate the daily return and find out the average of it : )
how can we calculate 252 daily returns? for one company, as it takes long time to do so
Use Excle, it just takes 30 secs to do this calculation 🙂
A similar Algorithm has been developed by us, which has given average returns of 70% per year, where all trades would be automatically placed into your own account. you can check http://www.returnwealth.com
Nice, btw have you checked this – https://developers.kite.trade/login , we basically give out APIs to trigger orders. You may find this helpful.
*i am not clear
HI Karthik,
I was trying to calculate the strike of nifty which is worth writing in this expiry, i have followed your steps explained in next chapter. my query
a) Can average daily return be negative. i have observed this while calculating avg mean for teh period 25.03.2015 to 23.03.2016. Due to this negative value i am getting a wrong nifty range for next 8 days(days left for march expiry).
b) I am still confused about number of days to be considered for calculating annualized daily SD and Annualized daily avg , should it be 365 or 248 in my case.
thank you . please correct if i am wrong
1) Yes, averages can be negative.
2) Stick to 365.
Due to negative average i am getting wrong range in which nifty will be trading for next one year.
and is Annual avg mean+ annual SD same as Annual SD+ Annual AVG mean, i am clear, because these both make a lot of difference while average is negative.
Please throe some light on calculations when average is negative.
thanks in advance
Will try and do this sometime soon.Thanks.
Awaiting your reply on my query of \” If I have to estimate the range for next 1 week, how many days data should I use to make these calcualations?\”
5 days.
Sir, If I have to estimate the range for next 1 week, how many days data should I use to make these calcualations?
How did you get Daily Average / Mean = 0.04%
Sir, I got it from your excel sheet. No need to reply on this query
Thanks 🙂
Add up all the returns and divide it over the number of days you will get the average.
if tatasteel daily volatility id 2.63 and i want to calculate 1sd then I should multiply 2.63 by square root of 30 or square root of working days in a month i.e22?
I feel that it should be sq root of 30 & not 22 because you are more concerned with the no. of days for which funds are locked if invested for 1 month. Am I right, Sir, Karthik Rangappa ?
30 is good I guess.
If you want the 30 day Vol, you will have to multiply with Square root of 30.
Sir, Fantastic reading material ……… I am reading it again and again to digest it fully …….. Some queries on the calculations of volatility. Will be grateful to you if you can attend the same …….
1. In your excel sheet, are the values displayed in columns G & H used only for plotting the graph of daily returns?
2. While arriving at the value of yearly average why have you multiplied the daily average by 252 & sq root of 252 when the actual no. of trading days from 29/07/2014 to 28/07/2015 are 244?
3. You have taken the sample data for 1089 days i.e. for 3 years approx. In Sharekhan\’s TradeTiger the data is available right from 06/09/2010 So, should we restrict the import of data to 3-4 years only? What should be the optimum size of the sample data?
Please revert.
Thanks & Regards.
CA. Prakash Tanak
1) G & H columns are basically creating bins and plotting a frequency of their occurrence. Of course, this is based on daily returns and used for plotting the graphs.
2) 252 is by practice, yes taking 244 would be more precise.
3) For short term trading, 2 year look back is good. With this calculate 2 year, 1 year, and 6 months volatility to get a fair reference.
Thanks for your prompt reply.
Welcome!
dear karthi,
i am confusing with sd and volatility both are same? please guide
Volatility is Risk as measured by Standard Deviation.
so if volatility of a stock is .80 then we can conclude that sd will .80 right? (
Yup, but do keep the time frame in perspective.
Dear Kartik,
How can i find out the % winning probabilities of Nifty Call Option and Put Options by taking the reference Nifty future price. I know this can be done in excel by entering the Nifty future price, Nifty Call option Strike, Nifty Put option Strike , Call option implied volatility, Put option implied volatility , Days to expiration. In excel there is a function called normdist or normsdist through which it can be done. I tried doing it but not coming correct. Can you help me out if you know the excel function.
Replied earlier.
Dear Kartik,
How can i find out the % winning probabilities of Nifty Call Option and Put Options by taking the reference Nifty future price. I know this can be done in excel by entering the Nifty future price, Nifty Call option Strike price, Nifty Put option Strike price, Call option implied volatility, Put option implied volatility , Days to expiration. In excel there is a function called normdist or normsdist through which it can be done. I tried doing it but not coming correct. Can you help me out if you know the excel function.
Not sure Sanjoe. The normdist function in excel is used in the context of normal distribution. What you are asking for may not be implementable using this (at least as far as i know).
Hi karthik , i calculated mean for nifty based on last one year data (08-12-2014 to 07-12-2015), i got mean as -0.03, should we consider negative value or absolute value while calculating upper and lower ranges???
Take the actual value and not really the absolute value.
Dear Karthik,
I have done a Nifty analysis according to the 1SD, 2 SD and 3 SD . But i need to check it with you whether all the calculations done by me are right. When i tried i found that its not attaching excel files. So can you give your email id so that i can send my attached working file to you.
Thanking You,
With Regards,
Sonjoe Joseph
Mob.No.94972-82865
Ah…can you please try and put up the numbers here itself?
Dear Karthik,
Please find the attached file were i have made my excel file in the png format. But i don\’t think now you will be able to see my formulas since its a picture file. Issues i\’m facing not able to apply the frequency formula and OED ie Option Expiry Date LL values are seen as NUM. Please also check all other values so that i can know whether i have applied the formula correctly. One suggestion in the Choose file also add other file formats then only we will be able to attach excel and word files.
Thanking You,
With Regards,
Sonjoe Joseph
Mob.No.94972-82865.
This link explains how to use the Frequency Fn – https://support.office.com/en-us/article/FREQUENCY-function-44e3be2b-eca0-42cd-a3f7-fd9ea898fdb9
Rest of the excel seems to be ok. Can you please apply the frequency fn and check once? Thanks.
Dear Karthik,
Attaching the file after applying the frequency but i think its wrong. Can you give yr email id so that you can check the formulas and can make any corrections if i have done anything wrong. This technique i will be applying in my trading so its better to correct any errors.
Regards,
Sonjoe Joseph.
Mob.No.94972-82865
Done.
Hi SONJOE JOSEPH,
I am also facing the same issue.
Please see the below link how to calculate the frequency. Go to you tube website and search as \”frequency function in excel 2010\” and please find the below screenshot also.
https://www.youtube.com/watch?v=IelRI5GD2Ik
Thanks for sharing the link Saravana !
Thanks saravana for the link.
Dear Sir,
Why and where this frequency function is to be applied/used ? Purpose ?
Usually to check for the distribution pattern of the data you are looking at.
Karthik
While calculating nifty\’s one year average & SD, you have taken 252 days(Solution 1), but while calculating for 1 month you took 30 days(Solution 2)… any specific reason?
This is the day count convention that NSE follows, hence sticking to the same.
How to convert log returns into simple returns.
How to do that in PC.
Sir, In the above example Nifty, How much period you have taken to calculate mean (o.o4%). i.e from which date to which date.
Regards
2011 to 2015…4 years I suppose. Please do check the excel.
Refer above and even you may lok at nifty range for next 30 days
Av.=0.04%*30=1.15. it should be 1.20% instead.
Thanks…will check this.
Daily Average / Mean = 0.04%
Daily Standard Deviation / Volatility = 1.046%
Current market price of Nifty = 8337
you have multiplied .04*252=9.66%. Please let me know as how you arrived at 9.66%.Can\’t it be 10.08%
Need to look into this, will get back shortly. Thanks.
Dear Karthik,
Amazing chapter the narration was exceptionally lucid.
However, there is some doubt whether stock returns follow \”normal distribution \”. I believe stock returns are more accurately represented by Student\’s -t distribution
Sunil – yeah, in a sense stock returns appear more \’peaked\’ hence Student\’s – t may fit the bill….my guess is this is especially true for stocks that have been trending well – like Kitex. However the idea here is to introduce the concept of simple distribution in the first place!
I would like to know how you calculated the Daily Mean. I noticed in the previous chapter you have mentioned the calculation from Standard Deviation but haven\’t mentioned on how to calculate the mean. Even if I take the average like you did for stddev the figure that you show is no where near to what I get. Also in the previous chapter you mentioned the daily volatility is 1.47% and in this chapter you take the daily volatility as 1.046% , is that a mistake ?
Sorry , I understood my mistake. Please ignore my comment.
Sure 🙂
What\’s wrong with calculations? Why it is showing Daily volatility 14% in excel sheet when it is 2.57% on NSE website? Please help me.
Is it because of Stock Split?If yes, What to do in such case? (I was talking about SBIN)
Ah, this could be because of stock split…besides I\’m assuming you are doing the calculations right. You can probably check here for historical data – https://in.finance.yahoo.com/q/hp?s=SBIN.BO ….guess they may have adjusted the data for splits/bonus etc.
Karthik sir!! many would have told you, but I would also like to tell u that you are great !! you are making tougher subjects easier and more easier. Thankyou so much!! :-),…
This is reassuring! Thank you so much:)
Hai Karthik,
Excellent work on making trading concepts simpler…
In module 5, the daily returns of different stocks and indices which are given, can u please tell me what\’s there on Y axis, as there are values
of daily returns on X axis…
Y-axis represents the number of days/value. For example (referring to the Nifty chart in section 17.4) – there are 90 days during which Nifty returned an average return of 0.26%.
Really awesome article Sir..
eagerly waiting for the option strategies chapters 🙂
Options strategies will start from next month…
In solution 1) 0.04%*252 is 10.8% where as it is printed as 9.66%, am i missing something here?
Ah! Blame that Excel. Its rounded it off to 0.04%….its in fact 0.0383248%*252 = 9.6578548% !
hi karthik, the difference between the upper range and lower range using SD for 30 days for HINDPETRO is quite substantial. it obviously would increase further with 2SD and 3SD. within such wide range wont it be a tedious task to select the right strike price? i am assuming there is a way to break through the clutter and finding the appropriate strike price. cheers.
Madhu – I think the up coming chapter (Volatility Application) will clear your doubt. Request you to please stay tuned.
Dear Karthik,
Thanks very much for ur Varsity initiative. I have learned about Options from ur writings, which I was not able to understand from other people writings. I earnestly request u to provide separate day trading n position trading in options, where we can use Gann levels, Fibonacci, Open Interest in put and call to understand what boundaries (strike prices) will be maintained and when the strike levels will be crossed etc.
Prasad – the next module is all about Option Strategies!
sir, how to tackle with gap up / gap down opening of nifty while trading nifty intraday options..?
Dint get that Abhijit – you are talking about gap up/down opening at the open right? So it should not really bother intraday traders.
ok…actually I was thinking about short strangle or short straddle strategy and what would happen if I take position at 3:15 pm and carried over night to take advantage of gap up / gap down opening of index on next day…am I right?
Short straddle or strangle etc are all delta neutral strategies…so gaps don\’t matter.
adds for every click !!??
As in? Sorry dint get that.
no need for you to sorry there was just a malware causing problems
Sure 🙂
Hi karthik, while converting daily volatility into annualized volatility of HINDPETRO there is a difference in the numbers published on NSE website and the one i calculated . also, the difference is significant if i take SQRT 252 ( difference 13 %) vis- a -vis SQRT 365 (difference 5%). does that mean the NSE is using 365 days to calculate the same?
Madhu – Yes NSE uses 365 days in their calculation.
Tumba tumba thnks Karthik for such simplified content 🙂
So what should we use, 365 or 252 for our calculation? And also for monthly calculation 30 or 20?
Namaskara 🙂
252 and 22 should do.
karthik,
when will we get the next chapters…..
This week Sarath.
While reading the change in volatility concept in a book i have noticed in an options example that premium is trading 0.78 rupees@14% volatility. If the volatility increases from 14% to 18% the premium also increased from 0.78rupees to 3.05 rupees? I don\’t know how they caluclated? Can you explain how the premiun is increasing if the volatility increase from 14 to 18%?
This is because of the effect of Vega. I will talk about it in detail very soon (maybe in chapter 20).
Hey, may I know the name of the book?
Again kudos to you sir…. Your effort to explain complex concept in simple and effective ways are simply superb:) particularly the question and answer part…great job sir…
Thanks Raghu!
The OI/Volume qty in Nifty 8350, 8450,8550…calls/put are less compare to 8300,8400,8500…calls/Puts qty. For eg If i short 8350 call/Put whether the full qty at limit price will get execute or any issue due to less liquidity? If yes whether can i able to buy back the qty once it reaches the target price as per the limit order?
Vasant, the OI information is on a daily basis. I\’m certain the OI for the strikes you have mentioned is large enough to even accommodate institutional orders 🙂
Am a Statistics graduate, I wish I have seen this post when I was in my college, amazing explanation. please include variance, regression, correlation as well in your coming chapters.
Thanks for the encouragement Karan. Will talk about these topics as and when its appropriate. Please stay tuned.
Next week.! Oh it\’s too late sir, pls update this week only..
Will try our best 🙂
Sir,
As usual eagerly waiting for next chapters :0 …kindly update
By next week for sure 🙂
Waiting for the next chapter.
By next week for sure 🙂
which means karthik, as per the wipro excel sheet you provided us as a download (chapter 16) , in which you have calculated its daily return. the formula application would be =average(c3,c245). that gives us 1.77% as daily average/mean. this figure has to be used along with the standard deviation to solve the e.g you have provided at the end of this chapter. would that be a correct assessment ? thanks.
Yup, you can. In fact in the coming chapter will give you more clarity on this aspect.
Hi, in the above e.g of nifty how have you calculated the daily average/mean as 0.04%. ? the earlier chapter talks of calculating the daily return using the log return. do you add the daily returns and divide by the number of observations?
do you add the daily returns and divide by the number of observations?
Raj – Yes, that\’s how average is calculated. However you can use excel function \’=Average()\’ to calculate the same in 1 shot.
How to convert log returns into simple returns.How to do that in PC.
Exponential of log should minus one should give you the simple return. Use can use excel for this.
Hello,
Fantastic Article, what a way to explain the things, simply superb!
All the initiatives taken by Zerodha (varsity, Taxation) are exceptionally good.
Best of luck to entire zerodha Team.
regards
Thank you so much Ajit!
Hello Mr Karthik,
I have one query…in the calculation of bin width, why did you divide difference of min and max by 50?
When I divide it over 50, the intention is to create 50 bins, I can in fact divide it by 100 or even 200. No restriction on that.
Adding to the above query..if i am adding data for the month of Aug in the Excel and trying to modify the data range in the frequency columns its not allowing…what i am doing wrong please help me with that.
Not sure Sharad, can you share a snapshot please?
Hi Karthik,
I\’m also facing the same problem while trying to change the FREQ formula in H14. The current formula is =FREQUENCY(E9:E1096,G14:G64). Now my data range has changed in col E, so I need to change that. When I\’m trying the same, it is giving the error message – \”You can not change the part of an array\”. Can you please look into this?
Thanks in advance.
Are you sure you are selecting the right date range? Also do pay attention to the Çtrl+shift+enter thing when using the frequency function.
Sir,
You r a doing a wonderful job teaching us the ABC of stock market trading.The brokerage rates of zerodha r also very low.
But many other brokerages have started giving low brokerages & also provide very good intraday F&O tips and also long term investment ideas based on technical & fundamental research
So,its my request that zerodha too start giving very good intraday F&O tips & long term ideas.It would make zerodha even more successful than it is now……
Pankit – Giving tips is like feeding a hungry man with 1 meal. But we have a slightly different philosophy – we believe in empowering people so that they don\’t go hungry again!
Hence we have all these educational initiatives like –
http://tradingqna.com/
http://zerodha.com/z-connect/
Wonderful. I agree.
Cheers!
We will discuss two important topics in the next chapter (1) How to select strikes that can be sold/written using normal distribution and (2) How to set up stoploss using volatility. This is what you say at the end of the chapter. What about selecting strikes for an option buyer using normal distribution? wont you be covering that? after all most of us would be buying options than selling them. appreciate your content and form of presentation. thanks.
Will cover that as well, please stay tuned 🙂
The way you simplifying the things which are complex to most of us, is fabulous. Many such things i never paid any heed till now. Thank you very much and keep going. we all are ready to grasp the knowledge you are sharing with us.
Thanks Shreya 🙂
Sir, one more question: You have shown predicting the price movement for the year and month. But it will also be needed to calculate the range of price for a day. i.e. present day or tomorrow to plan a trade. Will you explain that also?
Will be talking about this in the next chapter 🙂
Sir, In the Nifty eg you have taken data from 10th March\’11 onwards for the calculation. Obviously using more data for calculation wil provide the best result. But for precise caluclation how much data to be collected? Whether last 1year/2 year or anything? Kindly suggest..
In fact you can try this for any time frame…1 year , 2 year etc…you will end up with a normal distribution!
wonderful explanation ….was worth the wait :-).
small correction, I couldn\’t find the red arrow in the digram above the statement \”marked by a red arrow)\”. same for picture on Black Swan, also you have taken example of 1 to 10 slots but there are 13….may be pic needs to be changed….. ofcourse not a big thing…..
Yeah, i\’ve noticed the mismatch but cant too late to get the illustrations changed 🙂
Sir,
What a surprise journey. Pleasant surprise because maths use to be my favourite subject and i did not expect that I will get chance to use my skill in share market also. Now after this I (we) are more curious for the next chapter. I am eagerly waiting for it as you have said that this approach is different from the technical and fundamental approach.
Congratulation for again simple explanation and
Thanks for enlightening us.
R P HANS
Thank you! I hope you will like the upcoming chapter as well 🙂
So much clarity in your writeup. Pls share your twitter id 🙂
@karthikrangappa 🙂
Hello sir
i really liked the way you explained the topics, i have a small doubt i, e in nifty example in excel sheet while calculating 1SD yearly you used =k9*SQRT(252) As formula but i don\’t understand why it\’s 252 and not 365 days
please help me understand the same.
Thank you
252 represents the number of trading session in a year, hence 🙂
Very well explained. And very nice transition from mathematics to stock market application. You have a natural teaching ability and that can only come from a deep level of understanding.
Just one observation though – I understand that the trading year can be considered to have 252 days, In that case would it not be appropriate to consider that the trading month has 22 days instead of 30, in Solution 2 ( Nifty in 30 days)? Unless of course, one is trying to forecast the price 30 trading sessions later (instead of 30 days later?
Thanks for the kind words, Kartik 🙂
Yes, it does make sense to take 252 days a year / 22 per month.