

5.1 – Revisiting the Normal Distribution
If you have been a regular reader on Varsity, then chances are you’d have come across the discussion on Normal Distribution in the Options Module. If you’re not, then I’d strongly suggest you read up this chapter on Normal distribution.
This is a very important topic, I’d suggest you spend some time reading about it before you proceed. We will use the concept of Normal Distribution in both the techniques of Pair Trading, i.e the Mark Whistler’s Pair Trading technique, and the other technique we will discuss later on in this module. Given the central role it plays, you should spend time reading about it.
I’m reproducing the central theme around Normal distribution, this should serve as a quick refresher for people who are familiar with Normal Distribution, but for those who are not, I hope this does not demotivate you from reading the chapter on Normal distribution –
The general theory around the normal distribution which you should know –
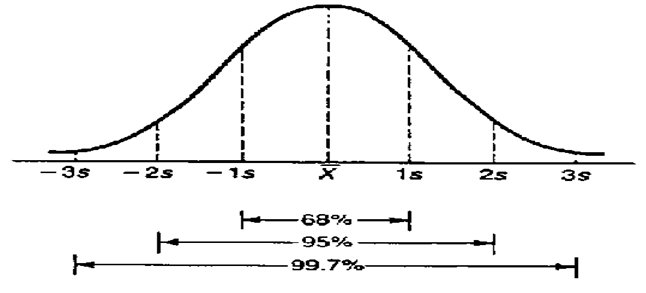
- Within the 1st standard deviation, one can observe 68% of the data
- Within the 2nd standard deviation, one can observe 95% of the data
- Within the 3rd standard deviation, one can observe 99.7% of the data
The following image should help you visualize the above –
Of course, there are other forms in which the data gets distributed – distribution such as uniform, binomial, exponential distribution etc. This is just for your information.
5.2 – Descriptive Statistics
In the previous chapter, we discussed three basic statistical metrics namely the Mean, Median, and Mode. We will now calculate these metrics on the pair data i.e the differential, spread, and ratio which we computed in the previous chapter. We will do these calculations using the excel functions.
Please note, I’m continuing on the excel that we were working on in the previous chapter, needless to say, you can download the updated excel from the link provided towards the end of the chapter.
The sheet is set up as below –
The Excel functions are as follows –
- Mean – ‘=average()’
- Median – ‘=median()’
- Mode – ‘=mode.mult()’
And the numbers are as below –
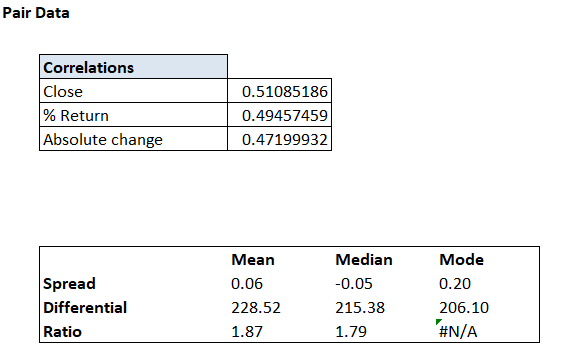
As you may notice, the correlation numbers were calculated in the previous chapter.
We now have the data setup. We need to add one key variable here and that would be the standard deviation. Again, standard deviation as a concept has been explained in Varsity earlier. I’d suggest you read this chapter to understand Standard Deviation better. Here is the summary though –
Standard Deviation simply generalizes and represents the deviation from the average. Here is the textbook definition of SD “In statistics, the standard deviation (SD, also represented by the Greek letter sigma, σ) is a measure that is used to quantify the amount of variation or dispersion of a set of data values”.
So in a sense, Standard Deviation gives us a sense of variability of the data or in other words, help us understand how widely the data set is spread out. Let me try and put this in the context of the Pair data we are dealing with.
The differential data which we computed a while ago is something like this –

Together there are 496 differential data points and earlier in this chapter, we have even calculated the average value across these data points i.e 228.52.
Now, what if I were to ask you to help me understand the variability of these data points from its average value? Or a better question to ask – why would I need to know the variability of the data points from its average value?
Well, if we don’t know the variability of the data, then there is no way we can make an intelligent assessment of the behavior of the data set. For example, when the 498th data is generated, we will know if this value is around the mean or within the range it varies.
This, in fact, forms the crux of pair trading.
Standard Deviation helps us measure this variation.
While I personally think standard deviation is good enough, there are traders who would also like to calculate another variable called the ‘Absolute Deviation’. Both standard deviation and absolute deviation help us understand the variability of the data. But they differ in terms of the way do they data is treated.
I was looking at the explanation to help you understand the difference between standard deviation and absolute deviation, and I found the following on Investopedia, which I think is quite nice. I’m taking the liberty of reproducing the content here –
“While there are many different ways to measure variability within a set of data, two of the most popular are standard deviation and average deviation. Though very similar, the calculation and interpretation of these two differ in some key ways. Determining range and volatility is especially important in the finance industry, so professionals in areas such as accounting, investing and economics should be very familiar with both concepts.
Standard deviation is the most common measure of variability and is frequently used to determine the volatility of stock markets or other investments. To calculate the standard deviation, you must first determine the variance. This is done by subtracting the mean from each data point and then squaring, summing and averaging the differences. Variance in itself is an excellent measure of variability and range, as a larger variance reflects a greater spread in the underlying data. The standard deviation is simply the square root of the variance. Squaring the differences between each point and the mean avoids the issue of negative differences for values below the mean, but it means the variance is no longer in the same unit of measure as the original data. Taking the root of the variance means the standard deviation returns to the original unit of measure and is easier to interpret and utilize in further calculations.
The average deviation, also called the mean absolute deviation, is another measure of variability. However, average deviation utilizes absolute values instead of squares to circumvent the issue of negative differences between data and the mean. To calculate the average deviation, simply subtract the mean from each value, then sum and average the absolute values of the differences. The mean absolute value is used less frequently because the use of absolute values makes further calculations more complicated and unwieldy than using the simple standard deviation.”
We will go ahead and compute both “Standard Deviation”, and “Absolute Deviation” for all the three pair data variables.
By the way, I’m interchanging the Y-axis to Mean, Median, and Mode. The X-axis to Differential, Ratio, and Spread. Given this, the snapshots posted above will be slightly different from the one posted below, hope you won’t mind my clumsy data handling skills J
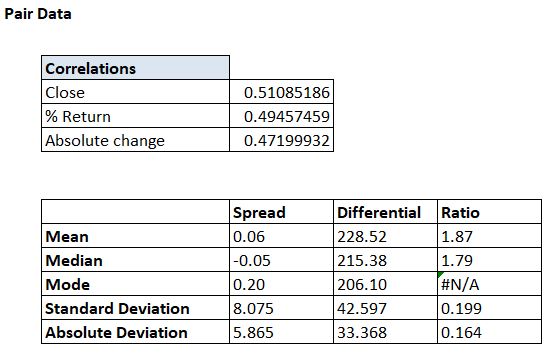
The excel function to calculate these variables are –
Standard Deviation – ‘=Stdev.p()’
Absolute Deviation – ‘=avedev()’
The Mean, Median, Mode, Standard Deviation, and Absolute Deviation is also known as the basic descriptive statistics.
5.3 – The Standard deviation table
The standard deviation as you know helps us get a sense of the variation in the data. We will now take this a step further and try and quantify the variation. Why do we need to do this, you may ask? Well, this will help us understand the extent of the variation from the mean value. For example, the 498th differential data could be 275, we will exactly know if 275 is way above the mean or way too below the mean.
With this information, we can choose to either buy the pair or short the pair. Of course, we will get into these details later on. For now, let us focus on quantifying the extent of the variation. In order to quantify the data point, we need to build something called as a standard deviation table.
The structure of the table is as below –
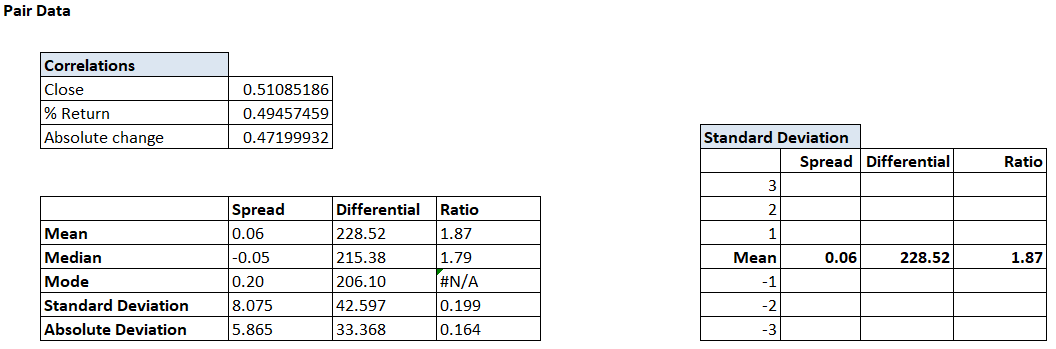
As you may have guessed, we are now going to calculate the values of 1, 2, and 3 standard deviations above the mean and below the mean, across spread, differential, and the ratio.
For example, let us just focus on the Spread data for now. The mean of the spread is 0.06. We also know the standard deviation (SD) is 8.075.
Therefore, the 1st SD above the mean would be –
0.064 + 8.075 = 8.139
2nd SD –
0.064 + (2*8.075) = 16.123
3rd SD –
0.064 + (3*8.075) = 24.288
These are all values above the mean. We can do the same to identify the values below the mean –
-1 SD –
0.064 – 8.075 = -8.011
-2 SD –
0.064 – (2*8.075) = -16.086
-3 SD –
0.064 – (3*8.075) = -24.160
I’ve done the same math across Differential and Ratio. Here is how the table looks –
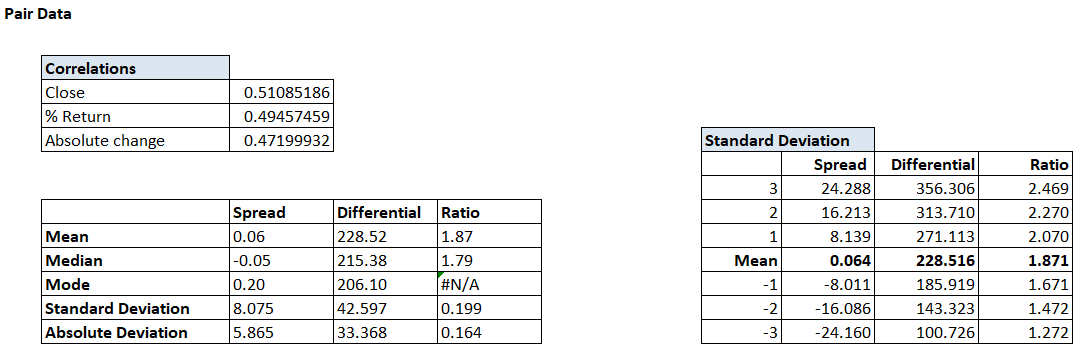
So if the 498th differential data read 315, then we can quickly understand that the value is around the +2 standard deviation and with 95% confidence you could conclude that there is only 5% chance for the next set of data points to go higher than 315.
Anyway, at this stage, we have almost all the data that we need to make the assessment of the pair and probably identify if there is an opportunity to trade. In the next chapter, we will go ahead and do this. In fact, I’ll start the next chapter with a quick recap of everything we have discussed so far, this is just to ensure we are all on the same page.
You can download the excel sheet used in this chapter here.
Signing of this chapter by wishing you all a very happy Xmas and a happy new year! Hope 2018 brings in wisdom, wealth, and peace your way.
Key takeaways from this chapter
- Normal distribution plays a pivotal role in pair trading
- Within the 1st standard deviation, one can observe 68% of the data
- Within the 2nd standard deviation, one can observe 95% of the data
- Within the 3rd standard deviation, one can observe 99.7% of the data
- Standard deviation and absolute deviation measures the variability of the data
- The standard deviation table gives us a sense of how the current data stands with respect to its expected variation
- The cues to trade the pair either long or short comes from the standard deviation table.
Hello Karthik Sir,
How much duration data should we take so that we can get a swing opportunity in some months, in a pair i took 2 years data and took the trade according to it and it hit SL as price crossed 3 SD, then after some days i took 5 years data and backtested it and found out according to the data the trade shouldn’t have been initiated as 5 years data created Big SD range and only 1 or 2 trade might come in a year. Can you please guide as how much duration data should we consider before placing a trade ?
Thanks,
Rahul, I think 2 years data is a good place to start.
Hello Kartik Sir, I initiated a trade on 2 SD and now the price have crossed 3rd SD, how extinct is that scenario thou, but what should i do in that scenario.
Statistically, it\’s rare, but then from a P&L perspective, it can be really painful 🙂. If I were you, I’d look at closing the position – From Karthik 🙂
So does it mean the reverting to mean is not happening here, if i can hold ignoring the P&L and its pain should i hold it in respect to it reverting to mean or exiting is the only solution. Thanks in advance
If it\’s a pain, then close the position. Your capital is telling you (beyond any other metric) that the P&L strain is too much.
Squaring the differences between each point and the mean avoids the issue of negative differences for values below the mean, but it means the variance is no longer in the same unit of measure as the original data.
Bit confusing.Can you simplify this?
Ah, not really. Can you please give bit more context?
I\’m late to the party. However, Thank you Karthik for rekindling my interest towards maths and explaining such a boring mathematical concepts in an interesting way.
Happy learning, Baranidaran!
just a thought.
through standard deviation I remembered the options ch when you were explaining about all this stuff back then, I thought will I have to calculate all of that before taking up a trade but when I started trading in options I saw that we don\’t really go through all of that process all the time before taking the trade its based on only some factors so why all of this
Thats right, over time you will develop an intuitive sense of how markets function and you\’ll get a different perspective with experience 🙂
I have checked all stocks pairs in futures with correlation above around 0.75. Pairs that qualified are (axisbank, icicibank) (Jindalsteel,tatasteel), (PFC,RECL),(ACC,AMBUJA CEMENT).
As u suggested i took last 200 trading day data.
I took ratio as the matric as suggested by you.
I also ran normal distribution test, t-distribution test on the ratio. In none of the above 4 pairs I found that none of the above 4 pairs were normally distribution. Appying standard deviation etc assumes that data set is normally distributed which is not the case here. Then, isnt the system flawed?
Secondly, For (ACC,AMBUJA CEMENT) pair and for (Jindalsteel,tatasteel) pair, I found that ratio of their closing prices are not even stationary. they are trending !! IF the returns of the two stocks are highly correlated, how is it possible that their ratio is trending !! please throw light on the issue.
Dear sir,
Following from, \”…two values occurring more then once… \”, I will try to explain as best as I can. The mode function is supposed to give me the most frequently occurring value in a data. But my differential time series has two values which both occur three time I believe due to pure coincidence.
I get 159.65 & 220.4 using MODE.MULT(). If I use MODE(), I get 220.4. So in the mode, median, mean matrix of spread-differential-ratio, I have two values to fit in the cell adjacent to Mode-Differential.
How/where do I go from here? I am calculating on Google Sheets in case. Here is the link: https://docs.google.com/spreadsheets/d/1nlGe_yaCbpDD1Rqx5FIoD1apmtPyQlLyMfvDnmLqqPk/edit?usp=sharing
(See Ratios tab) Additional suggestions are welcome.
Dear sir,
I was setting up my excel sheet for pair trading and I had downloaded previous two years data from NSE. While applying the functions, the mode of my differential has given me two values occurring more then once. What do I do? I now have a 3×3 matrix with an two values occurring thrice. Thank you.
Ah, Looks like an excel issue. I\’m not sure if I fully understand this, Arvind.
Can someone guide me, what should be the ideal historical data range while evaluating a pair for trade?
Thanks
At least 2 years.
Thank You.
Will keep taking your help.
Of course, happy reading!
Need your suggestion and permission Mr Karthik.
can I post my contact details or if you can share anyone\’s email id.
this will be a great help in term of learning and sharing common thoughts and discussion on related topics.
I mean this needs practice, like-minded people will be a great help.
Thank You.
Anil, no, that wont be possible as it violates people\’s privacy expectations 🙂
Any specific parameters of bollinger bands or the default one. I saw one zerodha chart which has MEDIAN, SD sigma values. Can i post the chart screenshot here ?
YOu can use the default for BB, that serves the purpose.
Hi Karthik,
Wonderful article. Thanks for sharing this. How can i apply standard deviation and median on charts .
Thanks,
Mihir
You can use Bollinger bands as a proxy for SD.
Wow man,
\”Standard deviation is the most common measure of variability….\” this para where you explain the Standart deviation, why we take square root of the variance to get SD and why in the first place we are squaring to get the variance is just amazing. Thanks mate.
Happy trading ( ;
Same to you!
what is the difference between stdev() and stdev.p()?
I guess STDEV is used when you are looking at the sample of the entire population. If the data set is the population, then stdev.p is used.
sir where have you calculated the average value across the data points when calculating the standard deviation??
Can you check the excle, please? Thanks.
hello sir,
ONGC/BPCL and ONGC/NTPC…pairs correlation is not good (0.38 and -0.12 for last 63 days), but co-integration for last 1 yr is <0.5, (0.48 and 0.26 for last 252 trading days).
In such a case can we ignore correlation readings? after all we need mean reverting pairs to generate profits.
your inputs are valuable..
thanks.
Yes, mean reversion is what really matters. I\’m slowly ramping up to co-integration model. Request you to stay tuned 🙂
☺️☺️
I think i am overturned…i m doing pair trading since 1 to 1.25yrs…there is no solid basis books on that…
Just drop above question because i observe coint is more relevant than coint in practical trading.
Thanks..i got my answer.
*Typo
Coint is more imp than correlation…what i mean to said…
Over the next 1 or 2 chapters, I\’ll wind up the basic Pair trading setup and move towards the linear regression model.
Cheers!
Mr.Karthik when is the next chapter going to be live? Eagerly waiting.
Next week.
Mr. Karthik this isn\’t a proper question, but I\’m a statistician looking to get into trading. Can you tell me, the more savvy traders like yourself and may be few fellow traders you know, what would be the average return on your capital month on month, while you trade full time? Please indulge in my curiosity, as it would help my in my decision making. I know there isn\’t a standard rate of return. But if you could put out a Conservative number. Thanks in advance.
Sundeep, this is a fair question to ask. Due to time constraints, I don\’t get to trade that often. When I do, most of my trades are market neutral and return on margin deployed vary from -5% to +25% per trade. Sometimes on options, the rate of return goes as high as 100%. Please note, these are on an individual trade basis. My long-term investments, however, have delivered a better and more consistent return, thanks to the bull market.
Mr.Karthik thanks a lot for the response. I can understand what you\’re saying here. I do have one question though. Would it be possible to make a return of say around 3 to 5% every month using a very intelligently programmed trading system? Using statistical arbitrage or some other trading strategies that suit our risk/return profile?
I\’m afraid to say no because I\’ve seen and known traders who can generate this kind of return. However, it is not a very straightforward task.
This is amazing, thank you for the amazing work you have done.
I was just wondering when Nithin and team are going to build the crypto currency exchange for India. I can understand how our government is reacting but I think there is a clear need and with 24 hours trading, I have seen people loosing sleep, you already have solutions which if implemented in crypto trading can do wonders.
I would love to help in something like that and most importantly I would like to use one.
Sameer, we would like to deal with regulated assets. Crypto is not, so I\’m not sure if this is something we would get into anytime soon. Thanks for offering to help 🙂
Hello sir I have query regarding your 9th module
Variance and covariance matrix
Query is – you calculate scrips covariance with each other scrip which makes it a bit complicated …..
Why not choose a common benchmark like nifty 50 and then calculate your covariance with it ….
Please let me know if my idea is correct or I need to understand the concept better
thanks !!!
Benchmarking with an index provides the Beta of the stock. Along with beta, we also need to know the risk of having multiple stocks in a portfolio or their co-movements. Hence the covariance is required.
kartikji
wishing you a very happy new year.
nice going
i m waiting for last one…the co-integration!!
best wishes…
and look back window for all mean, co-relation and co-integration if we r going to use day t/f.
Thanks and wish you the same, Akash. We are slowly moving towards the co-integration bit, request you to stay tunned 🙂
Hi Karthik,
Posted my query under TA module a couple of days ago but not sure if it caught your attention. Thus re-posting it here:
I place a short trade on TechM Fut(P: 497 SL 513 T: 463) few days ago and below points were matching with the checklist suggested:
1. Bearish Engulfing (prior trend- UP)
2. High was a couple of ticks above the resistance
3. Primary trend of the scrip- Downwards
4. RRR of 2:1
5. Volumes: well more than the last 10 days average
The stoploss as guided was selected the higher of the two wicks, which also happens to be the 52 week high for that scrip and target was the support. I’ve been holding this for 9 trading sessions now but it is constantly giving negative returns and eating away my capital (M2M). Should I continue holding it? Kindly advise…
Sorry to have missed it, Himanshu.
I looked at the chart – the primary trend is upwards. This implies that you need to be quick in booking profits when you take trades in the direction of the secondary trend. Also, your SL has not been reached, so you can technically hold on to it. If I were you, I\’d hold but watch for opportunities to book profits and get out, at the earliest.
Thank You very much for the guidance. Here\’s wishing you and team Zerodha great success and milestones in year 2018..:)
Thank you so much! Wishing you the same 🙂
Simply superb!!!
Kudos to you Karthik for writing this complex setup in such a lucid manner.
Eagerly waiting for your next chapters on Pair Trading and Option Calendar Setup.
Any timeline for this two setup completion ? Waiting impatiently for the next chapters:)
Thanks a million again for the excellent Varsity!!!
Regards
Deepu
Happy to note you liked the content, Deepu.
Unfortunately, I cannot put a timeline here. I\’ll push myself to finish these chapters as soon as possible.
Thanks Karthik for the reply. When we can see the next chapter:)
Hopefully by next week!
How will we know that you have posted the next chapter for pair trading? I think it will be a great idea if you post the updates in your twitter id or any other way that you deem fit.
Yes, we always update on our official twitter handle – @zerodhavarsity.
thank you
Cheers!
User registration is not allowed. Reason?
Which site are you talking about, Rohit.
This very website zerodha varsity is not allowing new user registrations
There is no need for registration at all, Rohit. You can post your queries freely.